논문제목: Parallel WaveGAN: A Fast Waveform Generation Model based on GANs with Multi-Resolution Spectrogram
저자: Ryuichi Yamamoto, Eunwoo Song, Jae-Min Kim
소속: LINE Corp, NAVER Corp
발표: ICASSP 2020
논문: https://arxiv.org/abs/1910.11480
오디오샘플: https://r9y9.github.io/projects/pwg/
- Parallel WaveGAN
- WaveNet[Oord16]을 빠르게 만드는 또 하나의 방법.
- 아예 non-autoregressive WaveNet을 GAN을 이용하여 훈련시킴.
- 기본적인 adversarial loss에 더하여 multi-resolution spectrogram loss를 더한 것이 중요했음.
- 이름은 Parallel WaveGAN라고 지었고, ClariNet[Ping19]보다 파라미터도 더 적고 생성속도도 더 빠름.
Story
WaveNet [Oord16]의 이후로 Neural Network을 사용한 생성모델은 오디오 합성 분야에도 중요한 역할을 하고 있음. 그리고 WaveNet의 느린 생성속도를 개선하기 위한 방법론으로 teacher-student framework을 사용한 여러 기술들이 소개되었음[Oord18][Ping19][Yamamoto19]. 이 방법들은 WaveNet의 지식들을 IAF-based 학생 모델로 전수해주는 방법인데, 사실 이렇게 하기 위해서는 잘훈련된 WaveNet 모델이 있어야 할 뿐 아니라 지식전수(probability density distillation) 방법에도 여러 시행착오가 필요함. 그런데 꼭 이렇게 번거롭게 distillation을 해야할까? GAN을 사용해서 바로 훈련시킬 수도 있지 않을까?
Parallel waveform generation based on GAN
Generator로 WaveNet 비스무리한 모델을 사용. 오리지널 WaveNet과 몇 가지 차이가 있는데, non-causal convolution을 사용하고, 인풋으로 가우시안 노이즈와 auxiliary feature(멜)을 받고, non-autoregressive 방식이라는 것. 이제 이 녀석은 Descriminator를 속여가며 학습을 해야 하는데, 이때 사용되는 로스는

Discriminator는 Generator가 생성한 샘플이 진짜인지 아닌지 구분할 수 있게 학습을 해야하는데, 이때 사용되는 로스는
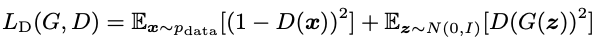
전체 구조는 이렇게 생겼음

Multi-resolution STFT auxiliary loss
Adversarial training의 안정성과 효율성을 높이기 위하여 multi-resolution STFT loss를 추가적으로 사용함. 먼저 싱글 STFT 로스[Yamamoto19][Arık19]는 다음과 같이 정의됨.



이 로스를 여러 종류의 파라미터셋(FFT size, window size, frame shift)을 이용하여 여러개로 늘림. 그리고 평균을 구해 aux 로스로 정의.

이렇게 하면 스피치의 여러 time-frequency 특성들을 골고루 학습시킬 수가 있음. 그리고 generator가 특정 STFT representation에 오버피팅되는 것도 막을 수 있음.
최종 로스는 두 로스를 함께 고려해서 정의. $\lambda_{adv}$는 4로 실험.

Experiments
전문 여성 일본어 스피커로부터 녹음한 내부 데이터를 사용. 총 23시간 데이터. Generator(Parallel WaveGAN)은 30개의 dilated residual convolution block 레이어로 되어 있고 discriminator는 10개의 non-causal dilated 1D convolution 레이어로 되어 있음.
훈련시 총 3개의 STFT 로스를 사용.

비교를 위해 Gaussian WaveNet과 그 parallel 버전을 사용(즉 ClariNet[Ping19]).
18명의 일본인에게 MOS를 측정한 결과는 다음과 같음.

STFT loss를 사용하면, 그리고 여러개 사용하면 확실히 품질이 좋아졌음. ClariNet에 대해서 adversarial training을 하면 차이가 없음. ClariNet보다는 낮은 점수를 받았지만 생성 속도는 2배정도 빠름. 모델 사이즈도 작고 distillation도 필요없기 때문에 훈련도 더 빨리됨. ClariNet 훈련하는데 12-13일;;; 이 걸렸지만 제안하는 기술은 2.8일 밖에 안걸렸음.

TTS를 실험하기 위하여 Transformer기반 모델을 훈련시킴. 인풋으로는 phoneme 시퀀스를 받고 멜을 출력하는 모델. 전체 구조는 [Ren19]를 따랐지만 일본어같은 pitch accent language를 좀 더 고려하여 수정함. Parallel WaveGAN을 보코더로 붙여서 완성.

이렇게 만들어서 TTS 실험을 하니 ClariNet보다 더 좋은 점수를 받을 수 있었음(거의 비슷하긴 하지만). GAN으로 훈련하는 것이 이득이 있는 것 같기도 함.
역시 오디오에서는 multi-resolution이 중요하고 또 중요한 듯
- [Oord16] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “WaveNet: A generative model for raw au- dio,” arXiv preprint arXiv:1609.03499, 2016. [논문리뷰]
- [Oord18] A. van den Oord, Y. Li, I. Babuschkin, K. Simonyan, O. Vinyals, K. Kavukcuoglu, G. van den Driessche, E. Lock- hart, L. C. Cobo, F. Stimberg et al., “Parallel WaveNet: Fast high-fidelity speech synthesis,” in Proc. ICML, 2018, pp. 3915–3923. [논문리뷰]
- [Arık19] S. O. Arık, H. Jun, and G. Diamos, “Fast spectrogram inversion using multi-head convolutional neural networks,” IEEE Signal Procees. Letters, vol. 26, no. 1, pp. 94–98, 2019.
- [Ping19] W. Ping, K. Peng, and J. Chen, “ClariNet: Parallel wave generation in end-to-end text-to-speech,” in Proc. ICLR, 2019. [논문리뷰]
- [Ren19] Y.Ren, Y.Ruan, X.Tan, T.Qin, S.Zhao, Z.Zhao, T.Y.Liu. FastSpeech: Fast, robust and controllable text to speech. NeurIPS 2019. [논문리뷰]
- [Yamamoto19] R. Yamamoto, E. Song, and J.-M. Kim, “Probability density distillation with generative adversarial networks for high-quality parallel waveform generation,” in Proc. INTERSPEECH, 2019, pp. 699–703.



