제목: Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning
저자: Wei Ping, Kainan Peng, Andrew Gibiansky, Sercan O. Arık, Ajay Kannan, Sharan Narang, Jonathan Raiman, John Miller
소속: Baidu Research
발표: ICLR 2018
논문: https://arxiv.org/abs/1710.07654
- Deep Voice 시리즈의 3번째 버전
- fully-convolutional attention-based TTS system. 따라서 이전 모델들보다 훨씬 빠름. 그러면서도 오디오 품질도 대등하게 만듬.
- LibriSpeech ASR 데이터셋(800시간의 오디오, 2천명의 스피커)을 TTS에도 사용함
- 열심히 최적화 및 병렬코딩해서 하루에 천만 쿼리를 처리하는 시스템을 완성함
Story
TTS 시스템이 DL에 힘입어 열심히 발전하고 있음[Arık17][Sotelo17][Wang17]. 하지만 대부분 모델들이 RNN을 기반으로 하고 있음. 이걸 오로지 CNN 기반 Attention으로 만들어 더욱 빠르게 만들어보겠음. 그리고 ASR용으로 좋은 데이터셋(LibriSpeech)이 있으니 TTS에도 이 데이터셋을 이용해 보겠음. 이 분야에서 2000명이 넘는 스피커를 이용한 시스템은 처음임.
Model Architecture
한마디로 말하면 fully-convolutional seq2seq TTS 시스템. 크게 3가지 컴포넌트로 구성됨.
Encoder: textual features(character, phoneme, ..)을 internal representation으로 바꿈. 이는 (key, value)로 표현됨.
Decoder: iternal representation을 attention 메커니즘을 이용하여 저차원의 audio representation(멜)로 바꿈.
Converter: 디코더의 hidden state로부터 최종 보코더 파라미터를 계산함.
3가지 모두 fully-convolutional하게 구성되는데, decoder만 causal하게 구성됨.

Text Preprocessing
인풋 텍스트를 잘 전처리 하는 것은 퍼포먼스에 중요함. 여기서는 먼저 1) 다 대문자로 바꿈. 2) 중간 구두점(punctuation mark)들을 모두 제거함. 3) 모든 문장을 마침표 혹은 물음표로 끝냄. 4) 단어 사이에 스페이스를 특정한 separator 캐릭터로 바꾸어 표현하는데, 이는 스페이스의 길이가 다양하기 때문임(함께 발음되는 단어, 표준적인 스페이스 케릭터, 짧은 멈춤, 긴 멈춤등).
Joint Representation of Characters and Phonemes
사전을 이용하여 먼저 단어들을 phonetic representation으로 변경하는 것이 TTS시스템의 정석. 이 모델에서는 인풋으로 캐릭터만 받는 것 뿐 아니라, phoneme-only와 캐릭터-phoneme를 혼합으로(여기서는 phoneme과 phoneme stress embedding도 입력으로) 받을 수도 있음. 캐릭터는 phoneme 사전 혹은 grapheme-to-phoneme 모델을 통해 phoneme으로 변경됨. 만약에 사전에 없는 이상한 단어면 그냥 캐릭터 자체가 입력으로 들어와, 모델이 자체적 내재적으로 grapheme-to-phoneme을 배우도록 함.
캐릭터-phoneme 혼합입력인 경우, 훈련시에 매 반복마다 각 단어는 특정 확률로 phoneme representation으로 바뀌어 훈련하게 됨. 이렇게 하면 발음 정확도도 향상되고 어텐션 에러도 줄어들었음. 모델에서 phoneme representation을 지원한다면 잘못된 발음을 고칠 수 있는 것도 가능함. 좋은 기능임.
Convolution Blocks for Sequential Processing
주된 프로세싱 유닛으로 아래와 같은 convolution block을 이용함. 여기에서 c는 인풋의 길이를 뜻함.

1D convolution filter, gated-linear unit, residual connection, scaling factor($\sqrt{0.5}$) 등으로 구성됨. 스피커 정보도 넣기 위해서 speaker-dependent 임베딩이 바이어스처럼 더해짐.
Encoder
먼저 캐릭터 혹은 phoneme을 임베딩 레이어를 통해 벡터($h_e$)로 바꿈. 이 임베딩은 FC를 통과하여 타겟 차원으로 프로젝션됨. 그 다음은 앞에서 설명한 conv block을 여러번 거쳐 time-dependent text 정보를 뽑아내게 됨. 마지막으로 임베딩 차원으로 다시 돌아가 어텐션 key $h_k$를 만들어냄. 어텐션 value는 $h_k$와 $h_e$로 만들어짐.

즉 $h_e$는 로컬한 정보를 담고 있고, $h_k$는 long-term context 정보를 담고 있음. key($h_k$)는 뒤에 Attention Block에서 웨이트를 계산할 때 사용되고, 마지막 context 벡터는 value($h_v$)들의 가중합으로 계산됨.
Decoder
디코더는 autoregressive 방식(즉 이전 오디오 프레임으로부터 다음 오디오 프레임을 생성하는 방식)으로 오디오를 생성함. 오디오 프레임은 멜스펙트로그램으로 표현됨. [Wang17]에서와 마찬가지로 여러 프레임을 함께 디코딩하는 데 이러면 오디오 품질이 더 좋아졌음.
입력된 멜은 여러 FC레이어를 통과한 뒤 causal convolution과 attention block을 통과함. 여기서 인코더에 hidden state를 attend하는 query가 생성됨. 마지막으로 다시 FC레이어를 통과하여 다음 r 개의 오디오 프레임을 만들어내고 final frame 인지를 예측도 하게 함. 출력된 멜스펙트로그램에 대해서는 $L_1$로스가, final frame 예측에 대해서는 binary cross-entropy 로스가 사용됨
Attention Block
기본적인 dot-product 어텐션을 이용. 즉 attention weight를 계산하기 위하여 query와 key벡터가 사용되고, value 벡터의 가중합으로 context 벡터가 출력됨. key와 query에 (sin/cos 버전) positional encoding도 적용하니 어텐션 매커니즘이 더욱 개선되었음.
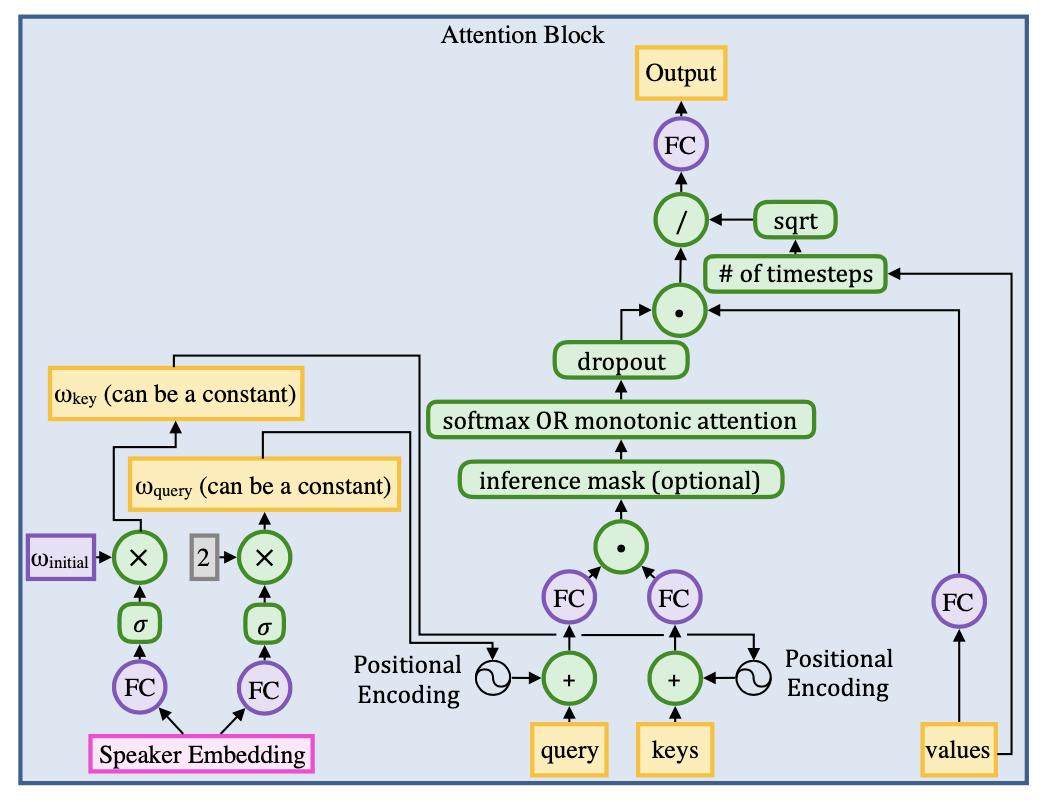
그 외에도 인퍼런스시에 어텐션 웨이트들이 monotonic하도록 constraint를 가하고, 소프트맥스를 계산할 때 고정된 윈도우 안에서만 하게 하는 등 몇가지 전략을 사용하니 오디오 품질이 더 좋아졌음.
Converter
마지막 컨버터에서는 디코더의 마지막 히든 레이어에서 나온 activation을 입력으로 받고 몇개의 non-causal convolution block들을 통해 보코더들의 파라미터들을 예측하게 됨. 다음과 같은 3가지 보코더를 사용하였음.
Griffin-Lim 보코더: Griffin-Lim 알고리즘은 반복적으로 phase를 예측함으로써 스펙트로그램을 오디오 웨이브폼으로 변경함. 여기에서 [Wang17]이 제안했던 sharpening factor를 이용하니 품질이 더 좋아졌음. 멜스펙트로그램에 대한 로스로 L1을 사용.
WORLD 보코더: [Morise16]에서 제안한 보코더로 파라미터로 1) voiced인지 아닌지 2) spectral envelope 3) aperiodicity 4) F0 을 예측하게 됨. 1)번만 cross-entropy로스, 나머지는 $L_1$ 로스를 사용.
WaveNet 보코더: 별도의 WaveNet을 훈련시켜서 사용함(파라미터로 멜스펙트로그램을 받음). [Arık17]과 유사한 형태의 구조를 하고 있지만 멜스케일 스펙트로그램을 사용한다는 점이 차이점.
Results
Data: 싱글 스피커 데이터셋으로 내부 영어 데이터(20시간)을 사용. 멀티 스피커 데이터셋으로는 VCTK(108스피커, 44시간)과 LibriSpeech(2484스피커, 820시간)을 이용.
Fast Training: Tacotron과 비교. 싱글 스피커 데이터셋의 경우 한번 이터레이션 시간이 0.06초였던 반면, Tacotron은 0.59초였음. 3가지 데이터셋 모두 DV3는 500K 이터레이션 정도 후에 수렴했는데, Tacotron은 2M 정도가 필요했음. 이렇게 빠른 속도는 fully-convolutional 아키텍쳐 때문일 것으로 생각.
Attention Error Modes: 어텐션을 기반으로 하는 TTS에는 몇 가지 에러가 발생할 수 있는데 예를 들어 1) 반복되는 단어들 2) 잘못된 발음 3) 중간에 단어들이 생략됨 등임. character와 phoneme을 동시에 입력으로 주고, 인퍼런스시에 monotonic constraint를 가하면 확실히 좋아졌음.

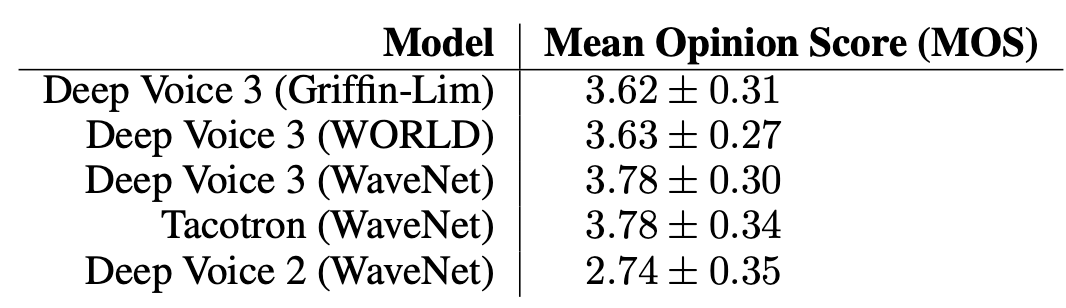
Naturalness: 보코더에 종류에 따라 결과의 차이를 MOS 점수를 통해 알아봄. Griffin-Lim보다는 WORLD가, WORLD보다는 WaveNet이 더 자연스러운 스피치를 만들었음. 하지만 WORLD보코더가 WaveNet보다 훨씬 더 빠르다는 장점은 있음. DV3이 DV2보다는 확실히 더 좋아짐. 그런데 잘 보니 DV3과 Tacotron의 WaveNet버전은 거의 차이가 안남(논문에서는 따로 언급은 없음). 사실 열심히 노력해서 그만큼 따라잡은 거임.
Multi-Speaker Synthesis: 멀티 스피커 데이터셋인 VCTK와 LibriSpeech로 훈련을 시켜서 비교함. DV3(WORLD)이 DV3(Griffin-Lim) 보다 좋음. 근데 DV2(WaveNet)보다는 점수가 안좋음. DV3(WaveNet)버전의 점수는 없는데 아마도 훈련시키는데 시간이 너무 오래 걸려서 빠진 듯. 만들었으면 아마도 DV2(WaveNet)보다 좋았겠지? Tacotron도 Griffin-Lim 버전만 만들어서 비교(그러니 점수가 그리 낮지).
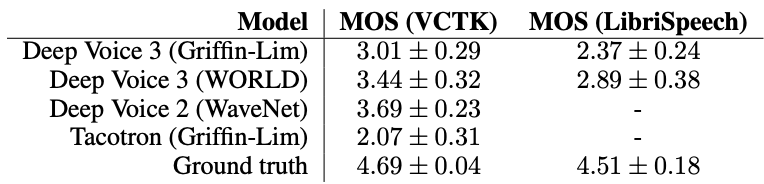
두 데이터셋을 비교하면 LibriSpeech 데이터셋의 결과가 VCTK보다 안좋은데, 데이터셋에 배경 노이즈도 많고 녹음 환경도 다양해서 그렇다고 함.
Optimizing Inference for Deployment: 열심히 노력해서 잘 구현해서 현실적인 TTS 시스템도 만들었다고 함.커스텀 GPU 커널을 구현하고 WORLD 보코더도 CPU에서 병렬화해서, 하루에 1천만 쿼리, 1초에 116 쿼리(QPS; queries per second)까지 처리가 가능했다고 함(20개의 CPU와 하나의 GPU서버 이용). 칭찬해줘야 함.
Deep Voice 시리즈 3탄.
어텐션은 TTS모델에도 적용하기 훌륭한 모델인걸로.
- [Morise16] Masanori Morise, Fumiya Yokomori, and Kenji Ozawa. WORLD: A vocoder-based high-quality speech synthesis system for real-time applications. IEICE Transactions on Information and Systems, 2016.
- [Arık17] Sercan O. Arık, Mike Chrzanowski, Adam Coates, Gregory Diamos, Andrew Gibiansky, Yongguo Kang, Xian Li, John Miller, Jonathan Raiman, Shubho Sengupta, and Mohammad Shoeybi. Deep Voice: Real-time neural text-to-speech. In ICML, 2017. [논문리뷰]
- [Sotelo17] J.Sotelo, S.Mehri, K.Kumar, J.F.Santos, K.Kastner, A.Courville, Y.Bengio. Char2wav: End-to-end speech synthesis. ICLR workshop 2017. [논문리뷰]
- [Wang17] Y.Wang, RJ Skerry-Ryan, D.Stanton, Y.Wu, R.Weiss, N.Jaitly, Z.Yang, Y.Xiao, Z.Chen, S.Bengio, Q.Le, Y.Agiomyrgiannakis, R.Clark, R.A.Saurous. Tacotron: Towards end-to-end speech synthesis. INTERSPEECH 2017. [논문리뷰]



