제목: FastSpeech: Fast, Robust and Controllable Text to Speech
저자: Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu
소속: Zhejiang University, Microsoft Research, Microsoft STC Asia
발표: NeurIPS 2019
논문: https://arxiv.org/abs/1905.09263
오디오샘플: https://speechresearch.github.io/fastspeech/
- FastSpeech
- 일단 기본적인 Transformer [Li19] 모델을 훈련시켜 teacher 모델을 만듬. 이 모델을 이용하여 attention alignment를 구하여 phoneme과 mel frame의 길이를 정확히 맞추도록 훈련함.
- 학생 모델은 Transformer기반 feed-foward network을 사용. 이러면 병렬로 처리도 가능하고 속도도 훨씬 빨라짐.
- sequence-level knowledge distillation[Kim16]을 이용하여 가르치니 더 잘 되었음.
- 이렇게 하니 1) 속도도 빨라지는데, 2) alignment도 잘 맞춰져서 오디오 품질도 좋아짐, 3) 그리고 alignment 부분의 스케일을 조정하여 결과 오디오의 속도도 조정할 수가 있음.
- 멜스펙트로그램 생성을 270배, end-to-end speech synthesis를 38배만큼 빠르게 할 수 있었음.
Story
Neural TTS[Ping18][Shen18]들이 좋은 결과를 보이고 있지만 단점들이 있음. 예를 들어 1) 다들 autoregressive방식으로 acoustic feature(e.g. 멜스펙트로그램)을 만들기 때문에 인퍼런스 시간이 상대적으로 길고, 2) 종종 결과들이 robust하지 않고(단어들을 건너뛰거나 반복하고), 3) voice speed 이나 prosody 등을 콘트롤하기도 힘듬. 이를 한번에 해결해 보겠음. 먼저 Transformer를 기반한 feed-forward network을 사용해서 인퍼런스 시간을 크게 줄이고, phoneme sequence와 mel sequence를 정확하게 매칭을 시키겠음. 그러면 결과도 robust하게 되고 이를 조정하면 스피드등도 콘트롤할 수 있음.
근데 최근에 non-autoregressive 방식이 나오지 않았음? Parallel WaveNet[Oord18], ClariNet[Ping19], WaveGlow[Prenger19]등이 그러한 방식인데, 사실 이건 non-autoregressive 보코더에 연구들임. 여전히 멜까지는 autoregressive하게 만드는 연구가 대부분. 거의 동시에 나온 ParaNet[Peng20]이 이 방식과 동일하게 멜까지 parallel하게 만드는 연구. 하지만 인코더-디코더를 사용해서 이 연구보다 속도가 더 느리고 robust에 대한 문제를 여전히 풀지 못한다는 단점이 있음.
FastSpeech
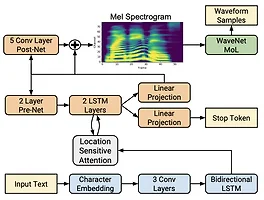
대부분의 seq2seq 모델이 인코더-디코더 모델을 사용하는 반면 여기서는 새로운 feed-forward 방식을 제안함. 일단 전체 아키텍쳐는 다음과 같음.

Feed-Forward Transformer
FastSpeech의 기본 구조는 Transformer와 1D Convolution을 사용한 feed-foward 구조임. 이 구조를 Feed-Forward Transformer (FFT)라고 부를거임. (아놔 네이밍 센스 보소-_- 이 바닥에서 저런 약자를 마음대로 쓰다니).
phoneme이 mel까지 가는데는 크게 2 x N 개의 FFT Block이 있고, 이 중간에는 phoneme과 mel frame의 길이를 맞추어주기 위한 length regulator가 있음. 각 FFT block은 multi-head attention과 1D convolutional network으로 구성되어 있음. 원래 Transformer구조와 비교하면 FC가 Conv1D로 바뀌었다는 것을 알 수 있음. 이는 speech의 경우 phoneme이나 mel 모두 가까이에 있는 hidden state들이 서로 더 가깝게 연관되어 있을 거라는 생각에서 나온 구조. 일리가 있음. 그 외에는 Transformer의 기본 구조를 따름.
Length Regulator
일반적으로 phoneme 스퀀스의 길이는 mel 프레임 길이보다는 작음. 즉 하나의 phoneme이 여러 멜 프레임에 해당됨. 따라서 이 길이를 맞춰줘야 함. 예를 들어 $H_{pho}$ = [h1, h2, h3, h4] 이고 $D$ = [2, 2, 3, 1] 이면, $H_{mel}$ = [h1, h1, h2, h2, h3, h3, h3, h4] 이렇게 늘어나게 됨. 여기에 파라미터 알파 $\alpha$를 추가해서, 이를 $D$에다가 곱해 전체 스피드를 조정할 수 있음. $\alpha = 0.5$이면 $D$ = [1, 1, 1.5, 0.5] = [1, 1, 2, 1] 이렇게 길이가 변화됨.
Duration Predictor
Length regulator안에서 사용되는 모델로 phomeme의 duration을 예측, 즉 하나의 phoneme이 몇 개의 멜프레임에 해당하는지 예측하는 모델임. 전체 모델 중간에 위치하고 있고 MSE 로스를 이용해 함께 훈련되는 모델임. 이렇게 훈련된 모델은 인퍼런스에서만 사용됨. 왜냐하면 훈련에서는 autoregressive teacher 모델에서 직접 phoneme duration을 사용할 수 있기 때문.
- 먼저 [Li19]에 따라서 autoregressive encoder-attention-decoder Transformer TTS 모델을 훈련시킴(teacher 모델)
- 이제 이 teacher 모델에서 attention alignment를 뽑아내는데, 멀티헤드이기 때문에 여러개가 있을 거임. 그 중에서 가장 diagonal한 어텐션을 고름
- 마지막으로 duration extractor에서 phoneme duration sequence $D$를 뽑아냄. 즉 하나의 phoneme의 duration은 위에서 뽑아낸 어텐션 헤드가 어텐드한 멜프레임의 숫자일거임.
Experimental Setup
데이터는 LJSpeech dataset을 이용(13,100개 영어 오디오 클립+텍스트, 약 24시간). 텍스트 시퀀스는 [Sun19]를 이용해 phoneme 시퀀스로 바꿈. 실험은 특히 TTS에서 어렵다고 생각되는 50개의 문장을 뽑아서 사용함.
Model Configuration
FastSpeech model: 6개의 FFT 블락을 사용. phoneme embedding, hidden size등은 모두 384개로 맞춤. 어텐션 해드는 2개 사용. 1D convolution의 커널사이즈는 모두 3. 멜의 차원은 80.
Autoregressive Transformer TTS model: teacher 모델은 1) duration predictor를 훈련시키기 위한 타겟으로 사용되고 2) sequence-level knowledge distillation[Kim16]으로 mel을 생성하기 위해 사용됨. 모델은 [Li19]과 동일.
Training and Inference
먼저 teacher 모델은 4 NVDIA V100 GPU로 훈련. [Kim16]방법에 따라 먼저 text sequence에 mel sequence를 teacher 모델을 통해 생성시키고 이 데이터 쌍을 FastSpeech 모델을 훈련하는데 사용함. 인퍼런스때 멜스펙트럼은 WaveGlow[Prenger19]를 이용하여 오디오로 변환됨.
Results
Audio Quality: MOS점수를 비교해 보겠음. 비교대상은 1) GT, 2) GT오디오를 멜로 바꾸고 WaveGlow로 바꾼 오디오, 3) Tacotron 2(WaveGlow 버전)[Shen18], 4) Transformer TTS(WaveGlow버전)[Li19], 5) Merlin[Wu16](WORLD 보코더 버전)임. 결과는 다음과 같음.

결과적으로 FastSpeech는 Tacotron2나 (teacher 모델인) Transformer TTS와 거의 차이가 안나는 오디오 퀄리티를 얻을 수 있었음.
Inference Speedup: teacher model(autoregressive model)과 인퍼런스 속도를 비교해봄. 당연히 빠를 것임.

일단 phoneme sequence에서 멜까지 만드는데는 270배정도 빠르고, WaveGlow를 이용하여 오디오까지 만드는데는 38배정도 빠름. 또한 parallel하다는 장점 덕분에 입력의 길이에 따라서 인퍼런스 시간도 크게 달라지지 않았음

Robustness: encoder-decoder attention 모델 같은 경우 attention alignment가 잘못되어서 반복이 일어난다던지 건너띈다든지하는 에러가 발생하는 경우가 있음. 하지만 FastSpeech에는 그러한 에러가 제거되었음

Length Control: FastSpeech는 voice speed를 조정할 수 있다는 장점도 있었음.

인접한 단어들 사이에 break를 넣을 수도 있는데(별도의 space character를 넣어서), 이러면 prosody가 좀 더 나아지는 효과가 있음.

Ablation Study
이 논문에서 원래 Transformer논문에서 제안한 FC레이어를 쓰지 않고 1D convolution 레이어를 사용했는데 이게 효과가 있을까? CMOS로 비교해본 결과 차이가 있었음. 그리고 sequence-level knowledge distillation도 효과가 있는지 비교를 해보았는데, 역시나 효과가 있었음.

역시 distillation을 잘해서 간단한 모델로 바꾸면 속도는 확실히 빨라짐.
- [Kim16] Yoon Kim and Alexander M Rush. Sequence-level knowledge distillation. arXiv preprint arXiv:1606.07947, 2016.
- [Wu16] Zhizheng Wu, Oliver Watts, and Simon King. Merlin: An open source neural network speech synthesis system. In SSW, pages 202–207, 2016.
- [Oord18] A.van den Oord, Y.Li, I.Babuschkin, K.Simonyan, O.Vinyals, K.Kavukcuoglu, G.van den Driessche, E.Lockhart, L.C.Cobo, F.Stimberg et al., Parallel WaveNet: Fast high-fidelity speech synthesis. ICML 2018. [논문리뷰]
- [Li19] N.Li, S.Liu, Y.Liu, S.Zhao, M.Liu, M.Zhou. Neural speech synthesis with transformer network. AAAI 2019. [논문리뷰]
- [Ping18] W.Ping, K.Peng, A.Gibiansky, S.O.Arık, A.Kannan, S.Narang, J.Raiman, J.Miller. Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning. ICLR 2018. [논문리뷰]
- [Shen18] J.Shen, R.Pang, R.J.Weiss, M.Schuster, N.Jaitly, Z.Yang, Z.Chen, Y.Zhang, Y.Wang, RJ S.Ryan, R.A.Saurous, Y.Agiomyrgiannakis, Y.Wu. Natural TTS synthesis by conditioning WaveNet on mel spectrogram predictions. ICASSP 2018. [논문리뷰]
- [Sun19] Hao Sun, Xu Tan, Jun-Wei Gan, Hongzhi Liu, Sheng Zhao, Tao Qin, and Tie-Yan Liu. Token- level ensemble distillation for grapheme-to-phoneme conversion. In INTERSPEECH, 2019.
- [Ping19] W.Ping, K.Peng, J.Chen. ClariNet: Parallel wave generation in end-to-end text-to-speech. ICLR 2019. [논문리뷰]
- [Prenger19] R.Prenger, R.Valle, B.Catanzaro. WaveGlow: A flow-based generative network for speech synthesis. ICASSP 2019. [논문리뷰]
- [Peng20] K.Peng, W.Ping, Z.Song, K.Zhao. Non-autoregressive neural text-to-speech. ICML 2020. [논문리뷰]