제목: End-to-End Adversarial Text-to-Speech
저자: Jeff Donahue, Sander Dieleman, Mikolaj Binkowski, Erich Elsen, Karen Simonyan
소속: DeepMind
발표: ICLR 2021
논문: https://arxiv.org/abs/2006.03575
오디오샘플: https://www.deepmind.com/publications/end-to-end-adversarial-text-to-speech
- EATS(End-to-end Adversarial Text-to-Speech)
- 텍스트 입력에서부터 오디오 생성까지 end-to-end 방식으로 생성되는 TTS시스템
- 일단 자기팀에서 만든 보코더 GAN-TTS[Binkowski20] 아래부분에 alignment 하는 부분을 붙여서 end-to-end 방식으로 만든 것 같은 모델.
- 그리고 전체 훈련에도 adversarial 방식을 이용했는데 이 훈련이 성공하게 하기 위하여 로스들을 몇개 붙임.
- DTW도 이용하고 non-linear interpolation방식을 이용하는 듯 몇가지 기술이 들어가 있음.
- 다만 결과는 2 스테이지 방식보다는 안좋은데, 사실 제대로된 비교를 하지 않았음.너무 바빴음?딥마인드가 이래도 되는거임?
- 주저자는 Jeff Donahue와 Sander Dieleman인데, 동전 던지기로 순서를 정했다고 함;
- 오디오 샘플예제 중 하나가 abstract를 읽어주는 샘플. 이건 제법 쌈박한 아이디어.
Story
여러 스테이지로 진행되는 TTS 파이프라인에는 사실 여러 문제가 있음. 예를 들어 각 단계마다 훈련해야 하는 데이터가 필요하고 시간도 더 많이 걸릴 수 밖에 없음. 하나의 스테이지로 짠 하고 끝내는 TTS가 있으면 좋을 텐데. 분명 어려운 문제이긴 하지만 지금까지 발전된 기술들을 잘 이용하면 가능할 수도 있지 않을까?
Method
이 모델의 목적은 character혹은 phoneme을 입력으로 받아 24kHz 오디오를 생성하는 것. 일단 모든 TTS에서 가장 문제가 되는 것은 인풋과 아웃풋을 잘 align하는 것. 이를 위해서 generator를 두 모듈로 나누는 데, 먼저 1) aligner는 인풋 시퀀스를 아웃풋이랑 일단 낮은 해상도(200Hz)로 맞추고 2) decoder는 이를 업샘플링하여 오디오 해상도로 높이는 역할을 함. 각 모듈은 모두 differentiable하기 때문에 end-to-end 방식으로 훈련할 수 있음. 또한 feed-forward convolutional network으로 구성하기 때문에 빠름. 일단 전체 구조는 아래와 같음.

decoder 부분은 GAN-TTS[Binkowski20]을 이용(어차피 자기들이 만든 모델). 단지 인풋이 aligner block에서 나온다는 차이가 있음. 각 단계에 speaker embedding을 넣어서 멀티 스피커 버전으로 만듬. GAN-TTS에서 제안한 multiple random window discriminators(RWDs)도 동일하게 사용. 그리고 인풋 오디오에다가 $\mu$-law 변환도 가함. 즉 훈련은 $\mu$-law 도메인에서 하지만 나중에 아웃풋은 역변환을 해서 사용.
generator를 훈련하기 위해 사용하는 loss function은 아래와 같이 정의함.

$L_{G,adv}$는 hinge loss를 사용한 adversarial loss인데, 특히 TTS 같은 모델에서 잘 맞는 것 같음. 일단 훈련과 인퍼런스가 빠르고, 실전에서는 (유명한) mode-seeking 성질이 있는데, TTS처럼 strongly conditioned setting에서는 이러한 behavior가 제법 유용함. 나머지 $L_{pred}$와 $L_{length}$에 대해서는 아래에서 이어서 설명함.
Aligner
먼저 token sequence($x$)는 dilated convolution + batch normalization + relu 스택($f$)을 이용하여 token representation($h$)으로 바뀜. $h = f(x, z, s)$인데, 여기에 latents $z$와 speaker embedding $s$가 들어감. 이제 각 token $h$는 각자의 길이($l$)가 MLP($g$)를 통하여 구해짐. $l_n = g(h_n, z, s)$. 여기에서는 relu를 사용하여 음수가 되지 않게 함. 다음으로 길이를 계속 더해서(cumulative sum) 각 token의 end position($e_n$)을 구하고, 각각의 centre position도 구함($c_n = e_n - l_n / 2$).
이제 계산된 position을 이용하여 non-uniform interpolation함으로써 token representation h를 200Hz해상도의 audio-aligned representation(a)으로 바꾸게 됨. interpolation weight는 타임 스텝 $t$와 $c_n$의 차이에 대한 softmax로 계산하는데, 계산식은 아래와 같음.

여기서 $\sigma$는 temperature parameter로 작용할 수 있음. 이제 이 weight를 이용하여 모든 타임스텝 $t$에 대한 $a_t$값을 구할 수 있음.

token length를 예측할 때, 각 토큰의 position을 직접 각각 계산하는 것이 아니라 이렇게 cumulative summation을 이용하여 계산하게 되면 자연스럽게 monotonicity을 적용할 수 있게 됨.
Windowed Generator Training
훈련하는 데이터의 길이는 무척 다양함(1-20초). 이를 padding을 넣어서 길이를 맞춰주는 것은 낭비가 심한 일. 그 대신 각 데이터에서 2초 윈도우를 씌여서 작은 데이터로 만들어서 훈련을 함. 샘플링 위치도 랜덤으로 uniform sampling함. 이를 training window라고 부르겠음. aligner는 이 윈도우 크기에 해당하는 200Hz의 audio-aligned representation를 생성하게 되고 이는 decoder로 들어감. evaluation할 때는 전체 utterance에 대한 audio-aligned representation을 모두 생성한 후 이를 디코더에서 오디오를 생성함.
Adversarial Discriminators
Random window discriminators: GAN-TTS에서 제안한 random window discriminators(RWDs)를 5개 사용함. 원래 GAN-TTS 논문에서는 text에 대한 conditional 버전도 5개를 사용했지만, 여기서는 그 부분은 생략함. 그대신 5개의 RWDs는 speaker에 대한 embedding은 조건으로 들어감.
Spectrogram discriminators: training window 크기의 오디오를 멜스펙트로그램으로 바꿔서, 즉 spectrogram domain에서의 discriminator도 고려함. 여기에서는 BigGAN-deep[Brock18]에서 사용한 discriminator의 구조를 약간 변형하여 사용함. 사실 멜스펙트로그램은 2D이므로 이미지로 생각하고 처리해도 별 이상이 없음.
Spectrogram Prediction Loss
이렇게 한번해보니 adversarial feedback만으로는 정확한 alignment를 구할 수가 없었음. 그래서 별도의 로스, 생성된 결과의 멜스펙트로그램($S_{gen}$)과 ground truth의 오디오로 생성한 멜스펙트로그램($S_{gt}$) 간의 $L_1$ 로스를 추가하기로 함.

audio domain보다 spectrogram domain에서 계산하는 것이 phase difference등에 덜 민감한다는등 여러모로 장점이 있었음. $S_{gt}$를 생성할 때 약간의 jitter (24kHz 데이터 기준으로 최대 +-60 샘플)를 넣었는데 이렇게 하니 artifact를 줄이는데 도움이 되었음.
여기서 adversarial feedback만으로 alignment를 제대로 구하지 못하는 것에서 likelihood-based autoregressive model과의 차이점을 볼 수 있음. autoregresssive model은 sequence step에 따라 훈련이 진행되기 때문에 alignment을 제대로 배우지 못하는 이슈가 발생하지 않는 듯. 그래서 adversarial training에서는 위와 같은 별도의 prediction loss가 필요함.
멜스펙트로그램이 오디오 분야에서 워낙 대중적으로 사용되는 기술이긴 한데 사실 정확히 표준화된 구현이 있는 것은 아님. 그래서 이 논문에서는 친절하게 멜을 구하는 pseudocode를 appendix에서 제공함.
Dynamic Time Warping
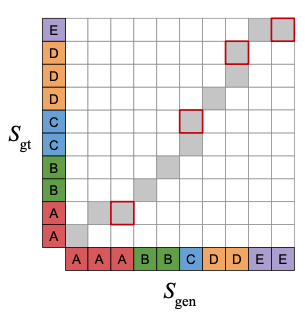
그런데 위 spectrogram prediction loss에서는 생성된 토큰 길이와 ground truth의 토큰 길이가 정확히 동일해야 한다고 가정하게 됨. 이 부분을 조금 완화하기 위해서 dynamic time warping (DTW)을 이용함. 즉 $S_{gen}$과 $S_{gt}$ 같의 minimal-cost alignment path $p$를 찾게 됨. 여기서 최소화하고 싶은 cost $c_p$는 아래와 같이 정의됨.

$p_{gen}$과 $p_{gt}$는 $S_{gen}$과 $S_{gt}$에서 찾은 각각의 path이고, $w$는 warping penalty로 각 path가 사이좋게 대각선으로 나아가지 않고 양옆이나 상하로 움직였을 때, 즉 warping이 일어났을 때 페널티를 주는 역할을 함. 이러면 과도한 와핑을 막아주는 효과가 있음. $\delta$는 와핑이 일어나면 1 아니면 0이 되는 indicator. $K_p$는 전체의 길이임. 자, 이제 DTW prediction loss는 아래와 같이 정의할 수 있음.
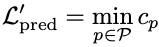
이러면 아래 그림처럼 예쁘게 warping된 alignment를 구할 수 있음.
DTW는 differentiable함. 하지만 위 식으로 사용한다면 gradient가 minimal path를 따라서만 흐르게 되므로 그리 좋지만은 않음. 따라서 이를 soft minimum버전으로 바꾸어 사용함.

이제 모든 feasible path를 따라 gradient가 알맞게 흐르게 할 수 있음. 물론 trade-off가 있음. 타우값을 크게 하면 최적화는 더 잘되겠지만 덜 정확한 minimal path를 따라 가게 됨. DTW에 대한 pseudocode도 논문 appendix에서 제공하고 있음(그냥 코드를 공개하면 안되겠음?).
Aligner Length Loss
마지막으로 보다 현실적인 token length 예측을 위하여, predicted utterance length를 ground truth lengh와 최대한 가깝게 만드는 로스를 추가하였음. $L$이 실제 utterance의 길이(200Hz에서)이고 $l_n$이 $n$번째 token의 predicted length라고 할 때, 로스는 아래와 같이 정의됨.
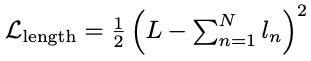
Text Pre-Processing
제안하는 모델은 character 인풋에 대해서도 잘 작동하지만, 사실 phoneme 인풋을 사용하면 샘플 퀄리티가 확실히 올라감. phoneme 변환에는 오픈소스인 phonemizer를 이용했음. 또한 텍스트나 phoneme이나 어느 인풋이든지 동일하게 훈련할 때 special silence token으로 앞뒤로 pad를 넣어줘서 aligner가 각 utterance 시작과 끝에 silence를 고려할 수 있게 만들었음.
Evaluation
Multi-Speaker Dataset: 훈련과 인퍼런스는 딥마인드 내부 데이터(69명의 남녀 북미영어 스피커들의 총 260시간)를 사용.
Results: MOS점수는 아래와 같음.

그런데 웃긴게.. 다른 시스템들의 MOS점수는 저 논문들에서 그냥 가져왔음. 데이터셋도 다르고 실험참가자도 달라서 당연히 정확하지 않은 비교일텐데.. 거기다가 점수들도 다 높음ㅋㅋ 어쩃든 EATS가 4점을 넘었다고 좋아함. 딥마인드에서 이렇게 비교 제대로 안해도 되는거임?
그 아래는 ablation study에 대한 결과. 각 메인 요소들이 다 중요하다고 나옴. 재미있는건 L_length와 L_pred를 뺴버리면 훈련이 아예 안되었다고 하고, 싱글 스피커보다 멀티 스피커의 결과가 좋은것은 그만큼 많은 데이터를 사용했기 때문이라고 생각됨.
아래는 훈련 데이터셋에서 가장 많은 4명의 스피커에 대한 결과로 구한 MOS결과.

일반적으로 데이터가 많을 수록 MOS가 높아지는데, 꼭 항상 그런것만은 아님.
Appendix
앞에서도 언급했듯이 몇개의 모듈에 대한 pseudocode를 비롯하여 이런저런 내용들이 논문뒤에 달려있는데, 한가지 볼만한건 지금까지 나온 주된 Neural TTS 모델들을 표 하나로 정리한 것이 있음. 각 시스템들이 어떤 스테이지로 구성되어 있고 어떤 방식으로 진행되는지를 적어놨는데 나름 잘 정리가 되어 있는 듯.

End-to-End TTS는 역시나 쉽지 않음.
그래도 이런 방향으로도 발전할 운명이긴 했음.
- [Brock18] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale GAN training for high fidelity natural image synthesis. In ICLR, 2018.
- [Binkowski20] M.Binkowski, J.Donahue, S.Dieleman, A.Clark, E.Elsen, N.Casagrande, L.C.Cobo, K.Simonyan. High fidelity speech synthesis with adversarial networks. ICLR 2020. [논문리뷰]



