논문제목: High Fidelity Speech Synthesis with Adversarial Networks
저자: Mikołaj Binkowski, Jeff Donahue, Sander Dieleman, Aidan Clark, Erich Elsen, Norman Casagrande, Luis C. Cobo, Karen Simonyan
소속: Imperial College London, DeepMind
발표: ICLR 2020
논문: https://arxiv.org/abs/1909.11646
코드: https://github.com/mbinkowski/DeepSpeechDistances (Frechet DeepSpeech Distance)
- GAN-TTS, 말그대로 GAN을 사용한 TTS(Text-to-Speech) 모델.
- discriminator를 여러 사이즈를 이용하고 랜덤하게 서브 샘플링하는 방법을 이용했는데, 그리고 컨디션 버전, 그냥 버전 총 10개를 사용했는데, 이렇게 하니 가장 좋은 결과를 얻었음
- 생성된 오디오의 결과를 quantative하게 측정을 위하여 Frechet DeepSpeech Distance, Kernel DeepSpeech Distance 매트릭 두 개를 제안함
Story
요즘 TTS의 성능이 많이 높아졌음. 특히 autoregressive 모델들[Oord16][Mehri17][Kalchbrenner18]의 성능이 좋긴한데 너무 느림;; 따라서 여럿 non-autoregressive 모델들이 제안 되었는데, 특히 flow-based model들[Oord18][Ping19][Prenger19][Kim19]이 주목할만함. 하지만 이제는 GAN이 나와야 할 차례겠지? 이제서야 최근에 조금씩 나오고 있는데[Donahue19][Engel19], 특히 MelGAN[Kumar19]에서는 text2mel 모델과 함께 스피치를 만드는 예제를 보여주고 있음. 여기서는 처음부터 linguistic feature와 $F_0$을 넣어서 스피치를 생성하게 함.
Dataset
딥마인드에서 자체적으로 가지고 있는 24kHz 오디오 데이터를 사용. liguistic features(phonetic + duration)와 pitch($F_0$)은 별도의 모델을 통해서 구했음. 총 44시간 데이터. 훈련할 때는 2초 윈도우를 사용했고, linguistic features와 pitch는 5ms 윈도우(200Hz)로 계산이 되었음. 즉 generator는 120배 만큼 업샘플링을 해야함. 데이터는 $\mu$-law transform을 적용을 했는데, 이렇게 변환하는 것이 결과가 더 좋았음
Generator
200Hz의 liguistic feature와 pitch를 인풋으로 받아 24kHz의 웨이브폼을 생성하는 생성자 모델.

7개의 GBlock으로 구성되어 있는데, 각각은 두 개의 residual block으로 되어 있음. dilated convolution을 사용해서 커다란 receptive field를 갖게 했음. Conditional Batch Normalization [Dumoulin17]을 사용. GBlock의 자세한 구조는 다음과 같음.
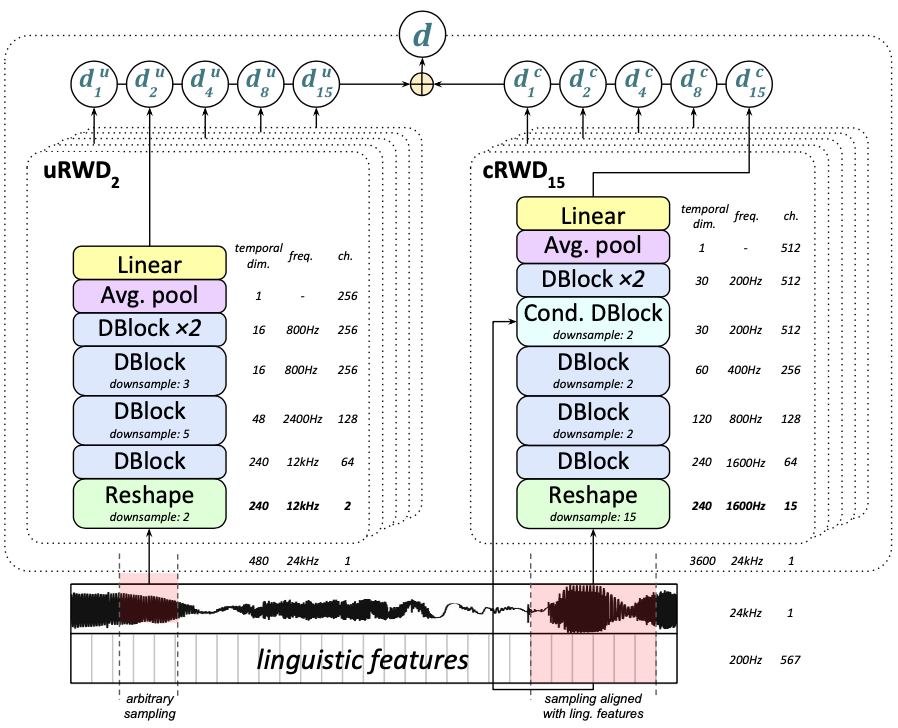
Ensemble of Random Window Discriminators(RWD)
Discriminator는 랜덤으로 서브 샘플링을 하는 여러개의 discriminator로 구성됨. 윈도우 사이즈는 5개(240, 480, 960, 1920, 3600 샘플) 그리고 피쳐들에 대해서 컨디션이 걸어지는 5개(cRWD), 아닌 것 5개(uRWD)해서 총 10개의 discriminator가 사용됨. cRWD는 얼마나 피쳐들이랑 맞는지, uRWD는 스피치가 얼마나 자연스러운지를 측정함. 이렇게 구성하면 data augmentation 효과도 있으면서 전체를 다 하지 않기 때문에 계산양도 줄어듬. 컨디션이 걸어질 때는 200Hz 단위에 맞게 조절됨. 구지 이를 수학적으로 나타내면 다음과 같이 쓸 수 있음
Discriminator Architecture
discriminator는 DBlocks이라는 모듈로 구성됨. feature를 조건으로 받는 conditional DBlock과 그렇지 않은 DBlock으로 나뉨.
전체 discriminator의 구조는 아래와 같음. 5개의 uRWD(왼쪽), 5개의 cRWD(오른쪽), 총 10개의 discriminator가 사용됨.
Evaluation
1000개의 문장을 만들어 사람들에게 얼마나 자연스러운지(naturalness) MOS를 측정하게 함. 이를 WaveNet [Oord16]과 Parallel WaveNet [Oord18]과 비교함. 모델에서는 2초 오디오 클립이 만들어지지만 이를 잘 연결하여(convolutional masking trick) 15초의 문장으로 만들 수 있음.
MOS외에 새로운 메트릭을 새롭게 제안하는데, 이름하여 Frechet DeepSpeech Distance, Kernel DeepSpeech Distance임. 냄새가 나겠지만, Freechet DeepSpeech Distance는 Frechet Inception Distance(FID)[Heusel17]의 오디오 버전임. Inception대신 DeepSpeech2[Amodei16]를 사용한다는 것이 차이점. Kernel DeepSpeech Distance는 Kernel Inception Distance(KID) [Binkowski18]의 오디오 버전인데, 두 distribution 사이의 Maximum Mean Discrepancy[Gretton12]를 구하게 됨. 참고로 [Kilgour19]에서는 Frechet Audio Distance라는 것을 제안했는데 거기에서는 audio event classification classifier를 훈련해서 사용함. 여기서는 speech recognition 모델을 사용함.
두 distance는 각각 조건이 걸린 버전(cFDSD, cKDSD)과 안걸린 버전(FDSD, KDSD)으로 나뉠 수 있음. 전자는 피쳐가 조건으로 있을 때의 distribution $p(X_G | c)$, $p(X_{real} | c)$의 차이, 후자는 그냥 $p(X_G)$, $p(X_{real})$ 두 distribution의 차이. 총 10000개의 샘플을 생성해서 계산을 했음.
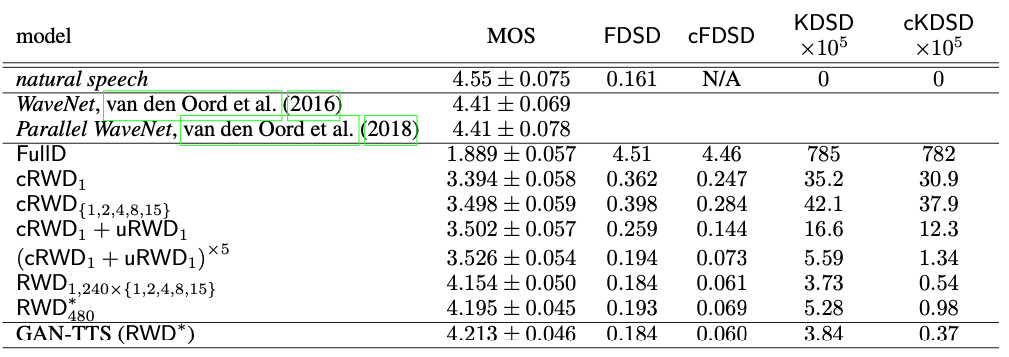
결과는 위와 같음. 이렇게 저렇게 모델을 바꾸고 다 해봤는데, 제안한 모델이 가장 좋은 결과를 얻을 수 있는 모델이었음. 가장 중요한 부분은 여러개의 RWD를 사용하는 것이었음. 세세하게 차이가 있지만 10개의 discriminator를 모두 사용한 모델의 점수가 거의 비슷했음. 전체 결과는 WaveNet에 비해서는 아직 부족하긴 하지만 그래도 머 거의 돈돈이라고 생각할 수 있음. 또한 MOS와 제안한 FDSD, KDSD와의 correlation도 제법 잘 나왔음. 괜찮은 메트릭이라는 뜻.
오디오 분야에서의 GAN은 discriminator가 역시 중요했음.
TTS도 잘 되네.
- [Gretton12] A. Gretton, K. Borgwardt, M. Rasch, B. Scho ̈lkopf, and A. Smola. A kernel two-sample test. JMLR, 2012.
- [Amodei16] Dario Amodei, Rishita Anubhai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro, Jing- dong Chen, Mike Chrzanowski, Adam Coates, Greg Diamos, Erich Elsen, Jesse Engel, Linxi Fan, Christopher Fougner, Tony Han, Awni Hannun, Billy Jun, Patrick LeGresley, Libby Lin, Sharan Narang, Andrew Ng, Sherjil Ozair, Ryan Prenger, Jonathan Raiman, Sanjeev Satheesh, David Seetapun, Shubho Sengupta, Yi Wang, Zhiqian Wang, Chong Wang, Bo Xiao, Dani Yogatama, Jun Zhan, and Zhenyao Zhu. Deep Speech 2: End-to-end speech recognition in English and Mandarin. In ICML, 2016.
- [Oord16] A.van den Oord, S.Dieleman, H.Zen, K.Simonyan, O.Vinyals, A.Graves, N.Kalchbrenner, A.Senior, K.Kavukcuoglu. WaveNet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016. [논문리뷰]
- [Dumoulin17] Vincent Dumoulin, Jonathon Shlens, and Manjunath Kudlur. A learned representation for artistic style. In ICLR, 2017
- [Heusel17] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. In NeurIPS, 2017.
- [Mehri17] S.Mehri, K.Kumar, I.Gulrajani, R.Kumar, S.Jain, J.Sotelo, A.Courville, Y.Bengio. SampleRNN: An unconditional end-to-end neural audio generation model. ICLR 2017. [논문리뷰]
- [Binkowski18] Mikołaj Binkowski, Dougal J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying MMD GANs. In ICLR, 2018.
- [Kalchbrenner18] N.Kalchbrenner, E.Elsen, K.Simonyan, S.Noury, N.Casagrande, E.Lockhart, F.Stimberg, A.van den Oord, S.Dieleman, K.Kavukcuoglu. Efficient neural audio synthesis. ICML 2018. [논문리뷰]
- [Oord18] A.van den Oord, Y.Li, I.Babuschkin, K.Simonyan, O.Vinyals, K.Kavukcuoglu, G.van den Driessche, E.Lockhart, L.C.Cobo, F.Stimberg et al., Parallel WaveNet: Fast high-fidelity speech synthesis. ICML 2018. [논문리뷰]
- [Donahue19] C.Donahue, J.McAuley, M.Puckette. Adversarial audio synthesis. ICLR 2019. [논문리뷰]
- [Engel19] J.Engel, K.K.Agrawal, S.Chen, I.Gulrajani, C.Donahue, A.Roberts. GANSynth: Adversarial neural audio synthesis. ICLR 2019. [논문리뷰]
- [Kilgour19] Kevin Kilgour, Mauricio Zuluaga, Dominik Roblek, and Matthew Sharifi. Frechet audio distance: A metric for evaluating music enhancement algorithms. In Interspeech, 2019.
- [Kim19] S.Kim, S.Lee, J.Song, J.Kim, S.Yoon. FloWaveNet: A Generative flow for raw audio. ICML 2019. [논문리뷰]
- [Kumar19] K.Kumar, R.Kumar, T.de Boissiere, L.Gestin, W.Z.Teoh, J.Sotelo, A.de Brebisson, Y.Bengio, A. Courville. MelGAN: Generative adversarial networks for conditional waveform synthesis. NeurIPS 2019. [논문리뷰]
- [Ping19] W.Ping, K.Peng, J.Chen. ClariNet: Parallel wave generation in end-to-end text-to-speech. ICLR 2019. [논문리뷰]
- [Prenger19] R.Prenger, R.Valle, B.Catanzaro. WaveGlow: A flow-based generative network for speech synthesis. ICASSP 2019. [논문리뷰]



