논문제목: UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
저자: Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, Juntae Kim
소속: Kakao Enterprise Corporation
발표: INTERSPEECH 2021
논문: https://arxiv.org/abs/2106.07889
오디오샘플: https://kallavinka8045.github.io/is2021/
- 기존 연구에서는 over-smoothing문제 때문에 full-band spectral features를 사용하지 않는 경우가 많았음. 근데 저 정보를 모두 사용하면 오디오의 퀄리티가 높아지지 않을까?
- 제안하는 UnivNet에서는 multi-resolution spectrogram discriminator를 사용하여 이 문제를 해결함. 그러니 역시 퀄리티가 더 올라갔음
Story
최근 GAN을 사용한 보코더 모델들이 많이 소개되고 있음[Kumar19][Yamamoto20][Kong20][Zeng21][Mustafa21]. 하지만 이들 모델에서는 대부분 high-frequency band까지 full-band spectral 정보를 사용하고 있지는 못함. full-band 멜스펙트로그램을 사용하는 모델에서는 over-smoothing 문제가 발생하여 오디오의 퀄리티가 떨어지는 현상이 발견.
그런데 voice activity detection 분야에서 여러 해상도(spectral + temporal)를 같는 피쳐들을 사용하면 좋은 binary classification 성능을 보일 수 있다는 연구가 있었음[Zhang15]. 어차피 discriminator가 하는 것도 binary classification인데, 여기에도 적용해볼까 생각이 듬. 그랬더니..
Generator
노이즈와 멜을 입력으로 받아 웨이브폼 오디오를 생성함. location-variable convolution(LVC)[Zeng21]을 추가하였는데, 더욱 좋은 성능과 속도를 얻을 수 있었음. LVC 레이어의 커널은 멜을 입력으로 받는 kernel predictor에 의해서 결정됨. 멀티스피커 데이터셋에서 generality를 향상시키기 위해서 gated activation unit(GAU)[Oord16]이 더해짐.
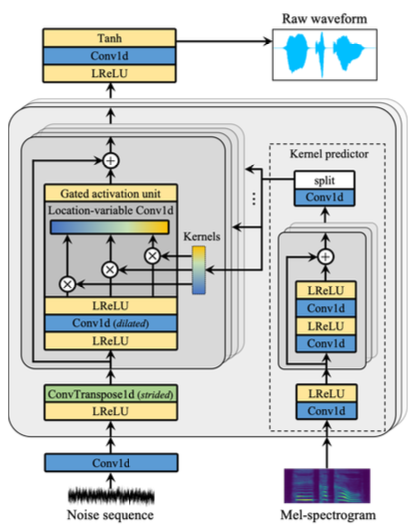
Discriminators
multi-resolution spectrogram discriminator (MRSD)는 오디오를 M개의 파라미터 셋에 의해 M개의 linear spectrogram으로 변경함. 이로 인해 다양한 temporal + spectral resolution을 같는 피쳐를 얻음. 이러면 full-band를 다 커버하는 높은 해상도의 시그널도 얻을 수 있음. 여기에 multi-period waveform discriminator (MPWD)[Kong20]도 추가함.

Training Losses
multi-resolution STFT loss[Yamamoto20]을 이용함. $L_sc$는 spectral convergence loss, $L_mag$는 log STFT magnitude loss.

여기에서 $s_m$은 $m$번째 MRSD sub-discriminator에서 계산된 값을 재사용하면 됨. LS-GAN[Mao17] 방식을 따라서 훈련하고, 전체 objective는 이렇게 정의.
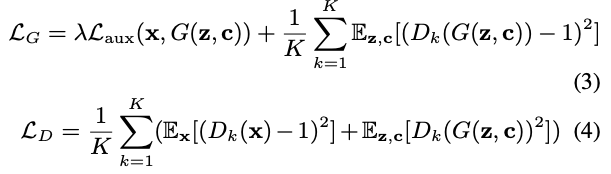
$D_k$는 $k$번째 MRSD와 MPWD sub-discriminator.
Experiments
- LibriTTS 데이터셋을 이용하여 훈련. 192시간 904 스피커, 116K의 데이터로 되어있는 풍족한 데이터셋. 이에 더하여 LJSpeech 데이터셋도 사용함.
- 메트릭으로는 AMT를 이용한 MOS와 PESQ[Rix01], linear spectrogram magnitude의 RMSE 값을 이용.
- 채널을 16개 가지고 있는 모델(UnivNet-c16)과 32개 모델(UnivNet-c32) 두 모델로 실험.
- STFT 파라미터 셋은 내부 실험을 통해 잘 골라봤는데 (FF의 포인트개수, frame shift 샘플, Hann window 샘플길이)=(1024, 120,600), (2048,240,1200), (512, 50,240)을 이용함.
- 모든 실험은 full-band (24kHz에서는 0-12kHz)에서 진행.
- TTS를 위해서 JDI-T[Lim20]를 이용하여 pitch와 energy를 계산하고, 오픈소스를 이용하여 text를 phoneme으로 바꿈.
Results
Ablation study: 아래에서 G1=LVC(location-variable convolution), G2=GAU(gated activation unit), D1=MRSD(multi-resolution spectrogram discriminator), D2=MPWD(multi-period waveform discriminator), D3=MSWD(Multi-scale waveform discriminator)[Kumar19]를 의미.

논문에서 제안한 모든 요소가 다 중요했는데, 특히 MRSD(D2)가 제거 되었을 때 over-smoothing 문제(특히 high-frequency band에서)가 나타나는 것을 볼 수 있음. 소리도 metallic artifact가 나타났음. MPWD도 퀄리티에 중요한 기여를 함. MSWD는 더 안좋은 결과를 보였음.

결과를 MelGAN, Parallel WaveGAN, HiFi-GAN와 비교해 보았음. MelGAN의 공식구현, HiFi-GAN의 공식구현을 이용했고, Parallel WaveGAN은 [Yamamoto20]에 따라 구현했음.

결과적으로 소타 HiFi-GAN 보다 더 좋은 결과를 보였고, 채널을 더 많이 사용한 모델(UnivNet-c32)이 좀 더 성능이 좋았음. Parallel WaveGAN에서 성능이 안좋게 나타난 것은 실험에서 full-band를 사용했기 때문에 over-smoothing 문제가 일어났기 때문으로 볼 수 있음.
discriminator도 multi-resolution spectrogram 버전으로 만드니 성능이 올라감.
역시 하나보다는 둘, 둘보다는 셋이 나음.
- [Rix01] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Perceptual Evaluation of Speech Quality (PESQ)-A New Method for Speech Quality Assessment of Telephone Networks and Codecs,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2001.
- [Zhang15] X.-L. Zhang and D. Wang, “Boosting Contextual Information for Deep Neural Network Based Voice Activity Detection,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 2, pp. 252–264, 2015.
- [Oord16] A. Van den Oord, N. Kalchbrenner, L. Espeholt, O. Vinyals, A. Graves et al., “Conditional Image Generation with PixelCNN Decoders,” in Advances in Neural Information Processing Systems (NeurIPS), 2016.
- [Mao17] X. Mao, Q. Li, H. Xie, R. Y. Lau, Z. Wang, and S. Paul Smolley, “Least Squares Generative Adversarial Networks,” in Proceedings of the IEEE international conference on computer vision (ICCV), 2017.
- [Kumar19] K. Kumar, R. Kumar, T. de Boissiere, L. Gestin, W. Z. Teoh, J. Sotelo, A. de Brebisson, Y. Bengio, and A. Courville, “MelGAN: Generative Adversarial Networks for Conditional Wave- form Synthesis,” in Advances in Neural Information Processing Systems (NeurIPS), 2019. [논문리뷰]
- [Kong20] J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis,” in Advances in Neural Information Processing Systems (NeurIPS), 2020. [논문리뷰]
- [Lim20] D. Lim, W. Jang, G. O, H. Park, B. Kim, and J. Yoon, “JDI-T: Jointly trained Duration Informed Transformer for Text-To-Speech without Explicit Alignment,” in Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2020.
- [Yamamoto20] R.Yamamoto, E.Song, and J.M.Kim. Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram. ICASSP 2020. [논문리뷰]
- [Zeng21] Z. Zeng, J. Wang, N. Cheng, and J. Xiao, “LVCNet: Efficient Condition-Dependent Modeling Network for Waveform Generation,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021.
- [Mustafa21] A. Mustafa, N. Pia, and G. Fuchs, “StyleMelGAN: An Efficient High-Fidelity Adversarial Vocoder with Temporal Adaptive Normalization,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021.



