논문제목: GAN Vocoder: Multi-Resolution Discriminator Is All You Need
저자: Jaeseong You, Dalhyun Kim, Gyuhyeon Nam, Geumbyeol Hwang, Gyeongsu Chae
소속: MoneyBrain Inc
발표: INTERSPEECH 2021
논문: https://arxiv.org/abs/2103.05236
오디오샘플: https://deepbrainai-research.github.io/gan-vocoder/
- 요즘 GAN을 사용한 보코더들이 이렇게 잘 되고 있는데 그 이유가 뭘까?
- 혹시 multi-resolution discriminator를 사용하기 때문이 아닐까?
- 이런저런 generator들을 만들어서 실험을 해보니, 우리 생각이 맞는듯.
Story
요즘 오디오 생성 분야에서 가장 좋은 성능을 보이는 기술 중 하나는 무엇보다 GAN임. 최근 모델들[Yamamoto20][Jang20][Song20][Yang20][Kong20]은 기존의 강자들인 autoregressive 모델들이나 flow-based 모델들을 효율성 뿐 아니라 MOS등 정성적인 기준으로도 이기고 있음. 그런데 왜 이렇게 GAN모델이 잘 될까 궁금하긴 함. 각 논문마다 여러 요소들을 제안하고 있지만, 혹시 이런저런 디테일들이 중요한 것이 아니라 다들 multi-resolution discriminator들을 사용한 프레임워크들이기 때문이 아닐까? 이런 가설을 한번 테스트해보도록 함.
Introduction
테스트 방법은 동일한 multi-resolution discriminator를 두고 총 6개의 다른 generator들로 훈련시켜 얼마나 결과가 차이가 나는지 보는 것. discriminator는 HiFi-GAN[Kong20]을 사용하는데, 여러 generator들과 연결하기도 좋고, 성능도 좋고, 공식구현도 있기 때문.
테스트한 generator는 아래와 같음
1) HiFi-GAN[Kong20]: 멜을 입력으로 받아 업샘플링을 하고 MRF(multi-receptive field fusion)이라고 부르는 multi-path residual block들을 지남. 공식구현을 이용.
2) MelGAN[Kumar19]: 처음으로 제대로 결과를 보인 GAN vocoder. 각 레벨마다 dilated convolution layer의 residual block을 쌓는데 그 이후 사실상 기본 베이스라인이 됨. 공식구현을 이용.
3) Parallel WaveGAN(PWGAN)[Yamamoto20]: 다른 모델과 달리 가우시안 노이즈를 입력으로 받음. 그리고 (non-causual) WaveNet 같은 구조를 generator로 사용한다는 것도 다름. 잘정리된 비공식구현을 이용.
4) Universal MelGAN(UMGAN)[Jang20]: MelGAN과 비슷하지만 residual block안에 GAU(gated activation unit)을 넣어 성능을 높임. 별다른 구현이 없어서 논문보고 직접 구현.
5) VocGAN[Yang20]: 다른 GAN보코더와 다른 점은 discrimination에서 generator의 중간입력과 최종입력을 모두 이용한다는 것. 업샘플링 스퀀스도 더 김. 비공식구현을 이용.
6) 여기에 더하여 새롭게 generator를 제안함. 아래에 계속 설명
Proposed Architecture
저자들의 다른 논문[You21]을 기반으로 하고 있는데, 아래 구조로 되어 있음. 오른쪽 Residual Block의 3개의 레이어는 각각 group-wise convolution, 1x1 convolution, exponentially increasing dilation을 하고, 이들이 12개로 연결되어 있어 총 8369샘플을 생성하게 됨. 멜 업샘플링에서는 transposed convolution대신 nearest-neighbor upsamling을 사용함. 사실 이 모델은 다른 5개의 generator를 섞어놓은 듯한 모습을 하고 있음. MelGAN 같은 residual 아키텍쳐에 WaveNet같은 skip 커넥션을 사용하고 PWGAN같은 latent-variable-dependent process를 가지고 있음. 즉 다른 generator들의 다양성을 모아놓은 듯한 모습을 하고 있는 generator.

Experiments
LJSpeech 데이터셋으로 훈련함. HiFi-GAN은 V2버전을 사용하는데, V1과 큰 차이가 없으면서도 파라미터가 적어 더 빨리 훈련되기 때문. 5개의 generator들이 훈련한 스텝도 다 다른데(400k ~ 2.5M) 중간 정도(700k)로 퉁침. TTS 실험에서는 Tacotron2[Shen18]의 구현을 사용.
총 340개의 샘플을 AMT를 이용해서 MOS를 구함. 또한 mel cepstral distortion(MCD)[Kubichek93]를 quantitative measure로 사용함. GT와 생성된 데이터를 MFCC로 바꾸고 이들을 time warping하여 얼라인하여 계산함.
Results
MOS점수를 확인해보니 제안한 모델의 점수가 가장 높긴 했는데, 사실 대부분 다 비슷하고 오차범위(confidence interval) 안에 있었음. 살짝 떨어지는 모델들도 있긴 함.
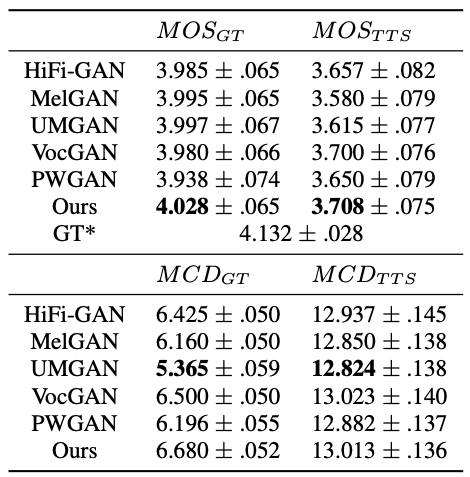
MCD점수들도 비슷한 상황이긴 한데, MCD_GT에서는 UMGAN의 결과과 다른 모델보다 더 잘 나왔음. UMGAN이 파라미터가 가장 많은 무거운 모델이긴 한데, 파라미터 때문인 것 같지는 않음. 다른 모델들은 딱히 파라미터 수로 정렬되지는 않았음. 이유는 잘 모르겠음.
참고로 6종류의 generator를 파라미터수와 속도등으로 정리하면 다음과 같음

Discussion
6개의 generator들은 파라미터수도 각기 사용한 아키텍쳐도 세세하게 다 다름. 하지만 결국 성능의 차이는 별로 없었음. 심지어 HiFi-GAN의 generator도 자신의 discriminator와 연결되었음에도 별다른 차이가 없었음. 즉 이들은 다들 좋은 generator들이고 만약에 좋은 discriminator(multi-resolution)과 연결된다면 이들의 디테일들은 보코더의 성능에 크게 영향을 주지 않는다는 것을 알 수 있음.
옛날에 나온 MelGAN이랑, 파라미터수가 10배가 차이가 나는 generator들도 다들 비슷한 성능을 보인다는 것은 사실 MelGAN이후로 generator에 대해서는 크게 성능향상이 없었다고도 볼 수 있음 MelGAN너는 멀 한거냐
알고보니 우리에게 필요한건 똘똘한 multi-resolution discriminator였음.
그나저나 재성씨 잘 살고 있지?
- [Kubichek93] R. Kubichek, “Mel-cepstral distance measure for objective speech quality assessment,” IEEE Pacific Rim Conference on Communications, Computers and Signal Processing, pp. 125–128, 1993.
- [Shen18] J.Shen, R.Pang, R.J.Weiss, M.Schuster, N.Jaitly, Z.Yang, Z.Chen, Y.Zhang, Y.Wang, RJ S.Ryan, R.A.Saurous, Y.Agiomyrgiannakis, Y.Wu. Natural TTS synthesis by conditioning WaveNet on mel spectrogram predictions. ICASSP 2018. [논문리뷰]
- [Kumar19] K. Kumar, R. Kumar, T. Boissiere, L. Gestin, W. Teoh, J. Sotelo, A. Brebisson, Y. Bengio, and A. Courville, “Melgan: generative adversarial networks for conditional waveform synthesis,” Advances in Neural Information Processing Systems (NeurIPS), pp. 14 881–14 892, 2019. [논문리뷰]
- [Yamamoto20] R.Yamamoto, E.Song, and J.M.Kim. Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram. ICASSP 2020. [논문리뷰]
- [Jang20] W. Jang, D. Lim, and J. Yoon, “Universal melgan: a robust neural vocoder for high-fidelity waveform generation in multiple domains,” arXiv preprint arXiv:2011.09631, 2020.
- [Song20] E. Song, R. Yamamoto, M. Hwang, J. Kim, O. Kwon, and J. Kim, “Improved parallel wavegan vocoder with perceptually weighted spectrogram loss,” arXiv preprint arXiv:2101.07412, 2021.
- [Yamamoto20] R.Yamamoto, E.Song, and J.M.Kim. Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram. ICASSP 2020. [논문리뷰]
- [Yang20] J. Yang, J. Lee, Y. Kim, H. Cho, and J. Kim, “Vocgan: a high-fidelity real-time vocoder with ahierarchically-nested adversarial network,” INTERSPEECH, pp. 200–204, 2020.
- [Kong20] J.Kong, J.Kim, J.Bae. HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis. NeurIPS 2020. [논문리뷰]
- [You21] J. You, G. Nam, D. Kim, and G. Chae, “Axial residual networks for cyclegan-based voice conversion,” arXiv preprint arXiv:2102.08075, 2021.



