논문제목: Adversarial Audio Synthesis
저자: Chris Donahue, Julian McAuley, Miller Puckette
소속: UC San Diego
발표: ICLR19
논문: https://arxiv.org/abs/1802.04208
코드: https://github.com/chrisdonahue/wavegan
사운드 샘플: https://chrisdonahue.com/wavegan_examples/
- GAN을 왜 오디오 생성에 사용하지 않지? 이 논문이 나온 2018-19년대에는 벌써 GAN이 나오고도 몇 년이 지나고 벌써 많은 발전이 이루어졌을 시기. 한번 GAN으로 웨이브폼 오디오를 만들어보겠음.
- WaveGAN과 SpecGAN이라는 두 가지 모델을 제안.이름도 먼저 찜
- 1초짜리 결과물들이지만, 그리고 결과도 그리 좋지는 않지만, 그래도 첫시도라는 것이 의미가 있음.
Story
2014년도에 좋은친구가 GAN(Generative Adversarial Networks)[Goodfellow14]를 제안하고, 그 뒤로부터 오랜 시간이 흘렀음. 요즘 ML에서 4-5년의 시간이면 엄청난 시간. 그동안 훈련방법도 많이 개선이 되고 퀄리티 좋은 이미지들도 이제 빵빵 나오고 있음. 그런데 아직까지 GAN을 사용한 오디오 연구는 찾아볼 수가 없음.
ML을 사용한 사운드 생성에서는 WaveNet[Oord16]같은 autoregressive 방법들이 대세를 이루고 있지만 너무 느림. 근데 GAN은 빠르잖아? 성공한만 한다면 좋을것임!
WaveGAN
DCGAN[Radford16]을 기본 모델로 사용함. 하지만 이미지는 2D, 오디오는 1D이기 때문에 5x5 2D 필터대신 25길이의 1D 필터를 사용. 그리고 업셈플링도 4씩 크게 함. 원본 DCGAN에서는 64x64 픽셀 이미지를 만들지만 오디오 샘플로는 너무 짧으므로 레이어를 추가해서 16384 샘플, 16kHz 기준으로 약 1초 살짝 넘는 결과를 만들게 됨. 결과가 1초밖에 안되지만 사운드 이펙트같은 용으로는 괜찮음(이라고 주장함). 배치 정규화는 사용하지 않았고, 훈련은 WGAN-GP[Gulrajani17] 즉 gradient penalty를 사용한 Wasserstein GAN을 사용.
generator와 descriminator의 아키텍쳐는 아래와 같음


transposed convolution을 사용하여 upsampling할 때, 그냥 그대로 사용하면 이미지에서 checkboard같은 현상이 일어남. 그런데 오디오에서 이러한 반복된 현상은 pitch가 있는 음으로 느껴지기 때문에 문제가 됨. 특히 discriminator가 제대로 배우지를 못함. 따라서 discriminator에서는 각 레이어의 activations의 phase를 $\pm n$ 샘플씩 랜덤으로 셔플링을 함. 이러면 discriminator를 더 똑똑하게 만들 수 있음.
SpecGAN
다음으로는 GAN으로 스펙트로그램을 만들게 해보겠음. 사실 이건 이미지 도메인이랑 같음. WaveGAN이랑 비교하기 위해서 이미지 사이즈도 128x128로 맞추고(그러면 동일하게 16384 샘플을 만듬) 아키텍쳐랑 훈련 방법도 거의 비슷하게 함. 마지막으로 만들어진 스펙트로그램에서 오디오를 만들기 위해서는 클래시컬한 방법인 Griffin-Lim 알고리즘[Griffin84]을 사용함
Experimental Protocol
Speech Commands Dataset에서 0부터 9까지 발음하는 부분만 빼내어 Speech Commands Zero Through Nine (SC09) 데이터셋을 만듬. 왠지 이상하게 기분상 MNIST와 비슷한 느낌이 들긴 하지만, 훨씬 고차원 데이터임(16000 >> 784). 각 단어마다 1850개씩 있고 총 5.3시간 데이터. 싱글 NVIDIA P100 GPU로 훈련을 시키니 WaveGAN은 4일만에 성공(200k iterations, 3500 epoches). SpecGAN은 더욱 빨리 훈련됨(2일, 1750 epochs).
Evaluation Methodology
생성모델의 평가는 항상 어려움. 완벽한 방법은 아니지만 이미지 분야에서 사용되는 inception score를 가져와 사용해보도록 함. SC09 데이터셋에 대해서 일단 FFT를 하고 멜스케일로 바꾸고 이미지를 만들어서 이를 분류하는 classifier를 훈련시킴.
하지만 inception score에서 알려진 몇가지 문제(클래스마다 샘플 하나씩 동일한 비율로 생성하거나, 오버피팅되면 좋은 점수를 받음)를 보완하기 위하여 1) $|D|_{self}$(셋 안에서 가장 가까운 example과의 가장 가까운 거리 평균), 2) $|D|_{train}$(실제 훈련 데이터안에서 가장 가까운 example과의 가장 가까운 거리 평균) 두 가지를 추가함. 이 값은 클수록 diversity가 크다고 생각할 수 있음.
하지만 사람에게도 실험을 해야겠지. AMT을 써서 사람들에게 생성한 10가지 숫자를 들려주고 숫자를 맞춰보게 함(acc). 또한 오디오의 품질(quality), 얼마나 쉽게 이해할 수 있는지(ease), 스피커들이 얼마나 다양한지(diversity)를 측정함(1-5).
Results and Discussion
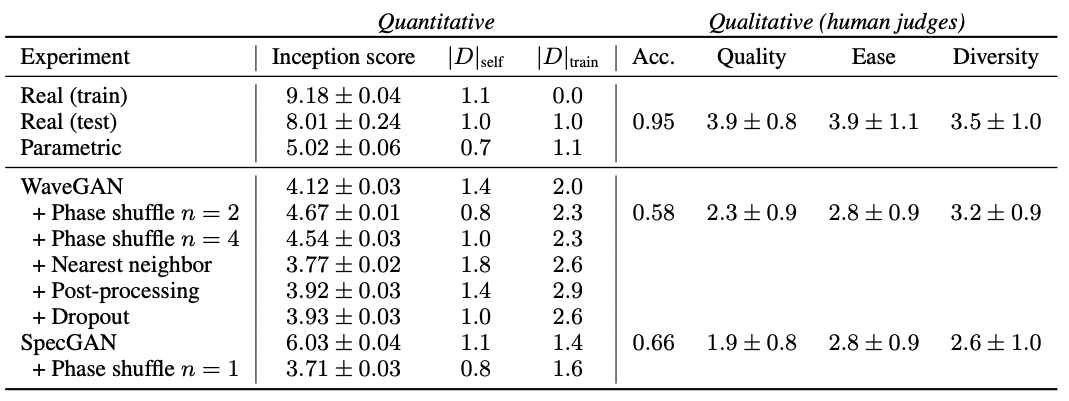
동일 데이터에 대하여 WaveNet[Oord16]과 SampleRNN[Mehri17]에 대해서도 실험을 해봤는데, 제대로된 결과가 안나왔음. 아마도 이런 작은 vocabulary speech에 대해서 컨디션을 안넣고 만들면 잘 안되는 듯 함. 그래서 사람 실험에서는 이들을 다 뺐음. WaveGAN에서 이런저런 실험을 해봤는데, 가장 잘되는건 phase shuffle(n=2)를 넣었을 때 였음. SpecGAN에서는 다른거 안하고 그냥 그대로가 결과가 가장 좋았음(inception score기준). |D|점수들은 모두 테스트 데이터보다 더 좋았는데, 더욱 다양하게 생성이 되었다는 뜻임.
WaveGAN과 SpecGAN을 비교하면, SpecGAN이 inception score나 사람들이 어떤 숫자인지 더 잘 맞추긴(acc) 했는데, 전체 사운드 퀄리티등에서는 WaveGAN이 더 나았음. 그런데 이는 어쩌면 Griffin-Lim 알고리즘에서 기인한 단점일 수도 있음. 누가 승자인지는 잘 모름.
SC09말고 4가지 데이터 다른 데이터셋(드럼, 새소리, 피아노, vocab speech)에 대해서도 실험을 해봤는데 신기하게도 WaveGAN이 좀더 원본과 가까운 스펙트로그램을 만들어내는 것 같음.

GAN을 이용한 오디오 생성의 초기논문.
결과가 만족스럽지는 않더라도 일단 먼저 빨리하는 것이 중요함!
- [Griffin84] Daniel Griffin and Jae Lim. Signal estimation from modified short-time fourier transform. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1984.
- [Goodfellow14] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. In NIPS, 2014.
- [Oord16] A.van den Oord, S.Dieleman, H.Zen, K.Simonyan, O.Vinyals, A.Graves, N.Kalchbrenner, A.Senior, K.Kavukcuoglu. WaveNet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016. [논문리뷰]
- [Radford16] Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016.
- [Gulrajani17] Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron Courville. Improved training of Wasserstein GANs. In NIPS, 2017.
- [Mehri17] S.Mehri, K.Kumar, I.Gulrajani, R.Kumar, S.Jain, J.Sotelo, A.Courville, Y.Bengio. SampleRNN: An unconditional end-to-end neural audio generation model. ICLR 2017. [논문리뷰]



