제목: Enabling Factorized Piano Music Modeling and Generation with the Maestro Dataset
저자: Curtis Hawthorne, Andriy Stasyuk, Adam Roberts, Ian Simon, Cheng-Zhi Anna Huang, Sander Dieleman, Erich Elsen, Jesse Engel, Douglas Eck
소속: Google Brain, DeepMind
발표: ICLR 2019
논문: https://arxiv.org/abs/1810.12247
블로그: https://magenta.tensorflow.org/maestro-wave2midi2wave (maestro)
추가결과: https://storage.googleapis.com/magentadata/papers/maestro/index.html
- 긴 음악(오디오)을 만들고 싶음. 일단 Music Transformer[Huang19]를 쓰면 심볼릭 음악은 1분간 만들 수 있음. 그다음에 이 음악 노트들로 컨디션을 걸어서 WaveNet[Oord16]을 이용하면 이를 사운드로도 만들 수 있음. 근데 이렇게만하면 좋은 논문이 안되잖아.
- Music Transformer로 음악을 만들려면 일단 재료 심볼릭 데이터가 많아야 하는데, 이 데이터를 많이 만들어보자구. 이름은 MAESTRO정도로 붙이고. 사실 예전부터 사용하던 Piano-e-competition 데이터인데, 이를 다시 잘 얼라인해서 3ms미만의 차이로 만듬. 이렇게 좋은 데이터가 만들어졌으니 전에 만들었던 Onsets and Frames[Hawthorne18]을 다시한번 훈련시켜보자구! 그러니 역시나 결과가 잘나오네.
- 그러다보니 Onsets and Frames -> Music Transformer -> WaveNet 논문을 묶어서 하나로 만들수가 있네! 나름 Wave2Midi2Wave 라고 이름 붙일 수 있는 프로세스도 됨. 왠지 논문들을 짜집기 한 것 같은 느낌같은 느낌이 들지만 전부 자기 회사 구글 논문들임. 누가 뭐라하겠음.
Story
WaveNet[Oord16]은 첫번째로 제대로 Neural Network써서 웨이브폼 오디오를 만들어내는데 성공하였음. 결과로 피아노 소리를 만들어내기도 했지만 조건을 따로 걸지는 않아 긴 소리를 만들어내지는 못했음. [Dieleman18]에서는 음악적 구조를 VQ-VAE로 모델링하고 이를 WaveNet으로 디코딩하여 더욱 긴 음악을 만들어 냈음. 하지만 결과가 그리 만족스럽지는 못함. [Manzelli18] 또한 MIDI로 컨디션을 준 후 WaveNet을 이용하여 첼로 솔로 음악을 만들어냈음. 하지만 훈련을 위해서 많은 양의 트레이닝 데이터가 필요했음. 그리고 모노포닉 음악이었음. 그래서 여기서는 오디오로 심볼릭 노트도 만들고, 심볼릭 노트로 긴 심볼릭 음악도 만들고, 이를 다시 오디오로도 만드는 모델을 제안함. 그러면 폴리포닉 음악을 길게 만들 수 있음.
Introduction
음악 오디오는 여러 타임스케일을 고려해야 하기 때문에 만들기가 힘듬. 예를 들어 피치는 짧은 타임 스케일, 리듬은 중간 길이정도의 타임 스케일, 음악 구조는 긴 길이의 타임 스케일을 가짐. 그런데 심볼릭 음들을 intermediate representation으로 사용하면 좋지 않을까? 웨이브넷에서는 이런 representation이 없어서 짧게(1-2초)는 들을만하다가 그보다 길어지면 카오스에 빠짐. 그래서 긴 음악 오디오를 만드는 것을 하나로 하긴 힘드니 3가지 모듈로 나누어서 해보기로 함.
(1) encoder $P(notes|audio)$: 오디오를 미디로 만듬. Onsets and Frames transcription[Hawthorne18] 쓰면 됨.
(2) prior $P(notes)$: 새로운 미디 음악을 만들어냄. self-attention-based music language model, 즉 Music Transformer [Huang19]쓰면 됨.
(3) decoder $P(audio|notes)$. 만들어낸 미디 음악으로 오디오를 만들어냄. WaveNet [Oord16] 쓰면 됨.
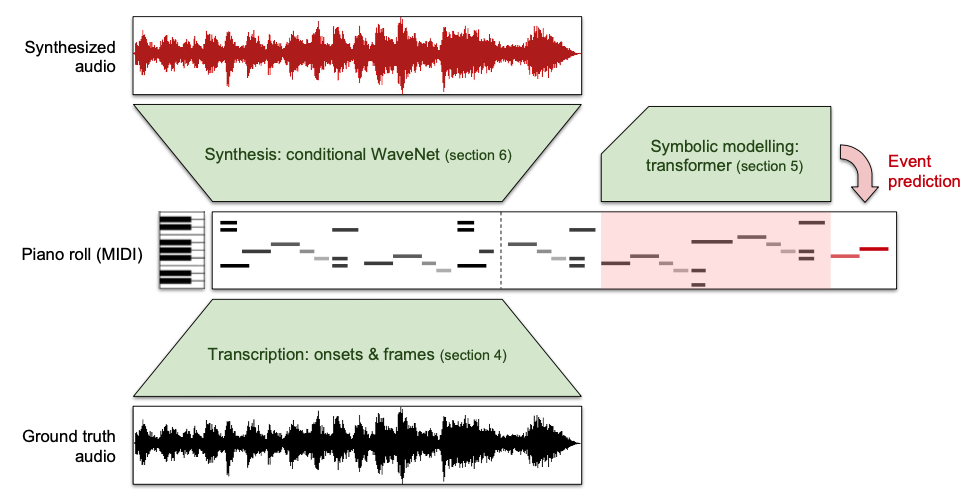
Dataset
International Piano-e-Competition이라는 대회가 있는데, 이 대회에서는 야마하에서 만든 Disklavier라는 피아노를 사용함. 근데 이 피아노는 연주자의 연주정보를 미디로 바꾸는 기능이 있음. 심사위원들도 비대면으로 심사를 하기 위한 목적이긴 한데, 오디오와 미디정보를 공짜로 얻을 수 있다는 장점도 있음. 이런 고급 정보를 구할 수 있다니! 구글이 파트너십을 맺어서 이 데이터를 많이 모음. 데이터셋은 MAESTRO(MIDI and Audio Edited for Synchronous TRacks and Organization)라는 이름을 붙임. 1184개의 연주, 172시간의 데이터, 100기가 좀 넘는 크기. 구글 스러운 스케일임. 공개도 되어있음.
참고로 그 외에 다른 데이터들은?
- MusicNet: 피아노외 다른 악기 연주도 있음. 레코딩 환경도 다양함. 하지만 얼라인먼트가 부정확할 때가 있음.
- MAPS: Disklavier 데이터와 미디 파일에서 합성한 오디오를 포함함. 따라서 전부 라이브 연주 데이터는 아님. 비율로 따지면 합성한 오디오가 더 많이 차지함.
- SMD: MAESTRO와 동일하게 Disklavier 데이터이지만 30배 적음.
Alignment
Disklavier에서 녹음된 미디와 오디오 파일이 있긴 하지만 사실 이 둘은 각각 따로 녹음됨. 그리고 녹음의 경우 레코딩 환경이 또 매년 다름. 그래서 실제로 음의 시작시간 및 길이등이 다름. 따라서 이를 정확히 맞추기 위하여 별도의 작업을 실시함(아마도 이 논문에서 가장 시간과 노력을 많이 들인 부분일 것 같음)
기본적인 방법은 미디를 FluidSynth를 이용해 사운드로 합성하고 실제 오디오 데이터와의 차이를 이용하는 것. 둘다 CQT로 변환하고 높은 MSE가 나오는 부분을 찾음. 얼라인은 Dynamic Time Warping을 이용함. DTW 계산할 때 모든 페어의 디스턴스를 다 계산하는 것이 아니라 Sakoe-Chiba band radius 안에 있는 거리만 계산함. 거의 잘 얼라인 되어있기 때문임. 논문 appendix에 2장에 걸쳐 자세하게 설명되어있음.
Piano Transcription
베이스라인으로는 Onset and Frames [Hawthorne18]을 이용함. 약간 수정을 했는데, (Kelz18에서 가져온) offset detection head를 더했고 LSTM사이즈와 CNN필터수, FC레이어수를 증가시켰음. 프레임 로스에 weighting을 사용하지 않았고 HTK frequency spacing을 이용하였음. 이 의미는 데이터가 많으니 모델을 더 크게, 그리고 좀 더 단순하게 만들어도 된다는 거임. 역시 데이터가 깡패.. 또한 audio augmentation도 사용해 봤음(SoX를 이용하여 랜덤하게 변환함). 근데 MAPS데이터셋에서는 도움이 되는데 MAESTRO에서는 오히려 성능을 저하시킴.
Music Transformer Training
Music Transformer [Huang19]의 디코더 부분을 이용하여 generative language model을 만듬. 참고로 논문에서는 이 페이퍼를 'An improved relative self-attention mechanism for transformer with application to music generation' 라는 이름으로 소개하고 있는데, 이 논문이 'Music Transformer' 로 이름이 바뀜. 역시 ml논문은 제목이 생명.
두 모델을 훈련시켰는데, 하나는 MAESTRO 데이터셋의 미디 데이터로, 다른 하나는 MAESTRO데이터셋을 Onsets and Frames로 트랜스크립션을 한 데이터(MAESTRO-T)로 만듬. transposition, time compression/stretching data 등의 음악 데이터에 대한 augmentation도 수행함.
Piano Synthesis
웨이브넷은 그럴듯한 악기소리를 만들어내지만 음악적 구조를 오래 보존하지 못한다는 단점이 있음. 하지만 우리가 미디시퀀스를 컨디션으로 넣어준다면? 웨이브넷은 로컬 스트럭처만 이용해서도 잘 만들것임. 오리지널 웨이브넷과 구조는 동일하지만 receptive field를 늘리고 레이어를 더 높게 쌓음. 이렇게 하니 더 잘 되었음.
재미있는 점은 웨이브넷이 피아노소리말고도 연주자가 숨쉬는 소리나, 연주장의 response나 청중들이 자리를 옮기는 소리같은 것도 만들어냄. 이건 사실 현실적인 사운드를 만들어낸다는 측면에서 좋은 거임. 긴 아웃풋의 경우 가끔식 음색이 갑자기 바뀌는 경우가 있었는데, 알고보니 매년 경연할 때마다 레코딩 환경이 달라서 그런 것이었음. 이 경우 컨디션으로 년도 데이터도 함께 넣으니 해결되었음.
Listening Tests
사람들한테 얼마나 실제 같은지 물어봄. 20초길이의 사운드를 들려줌. 실제 소리(Ground Truth)와 큰 차이를 안보임. WaveNet Ground/Test는 MAESTRO 테스트셋에서 랜덤으로 20초 길이의 MIDI시퀀스를 뽑아낸 뒤, 이를 조건으로 넣어준 WaveNet모델(MAESTRO Ground Truth 데이터로 훈련시킴). WaveNet Transcribed/Test는 오디오 데이터를 transcription한 데이터를 이용한 결과. 성능저하가 아주 살짝만 있었음.
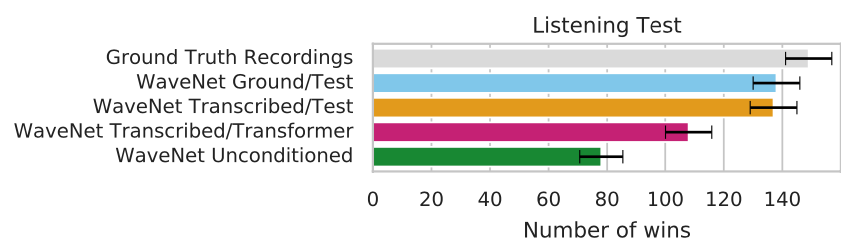
실제로 이 논문의 가장 큰 의미는 MAESTRO라는 데이터셋을 만들었다는 것.
이 데이터셋은 그다음부터 여기저기에서 많이 사용됨.
- [Oord16] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew W Senior, and Koray Kavukcuoglu. WaveNet: A generative model for raw audio. In SSW, pp. 125, 2016. [논문리뷰]
- [Dieleman18] Sander Dieleman, Aaron van den Oord, and Karen Simonyan. The challenge of realistic music generation: modelling raw audio at scale. arXiv preprint arXiv:1806.10474, 2018.
- [Manzelli18] Thakkar Vijay Manzelli, Rachel and, Ali Siahkamari, and Brian Kulis. Combining deep genera- tive raw audio models for structured automatic music. In 19th International Society for Music Information Retrieval Conference, ISMIR, 2018.
- [Hawthorne18] Curtis Hawthorne, Erich Elsen, Jialin Song, Adam Roberts, Ian Simon, Colin Raffel, Jesse Engel, Sageev Oore, and Douglas Eck. Onsets and frames: Dual-objective piano transcription. In Proceedings of the 19th International Society for Music Information Retrieval Conference, 2018. [논문리뷰]
- [Huang19] Cheng-Zhi Anna Huang, Ashish Vaswani, Jakob Uszkoreit, Noam Shazeer, Curtis Hawthorne, An- drew M Dai, Matthew D Hoffman, and Douglas Eck. An improved relative self-attention mechanism for transformer with application to music generation. ICLR 2019. [논문리뷰]
- [Kelz18] Rainer Kelz, Sebastian Bock, and Gerhard Widmer. Deep polyphonic adsr piano note transcription. In Late Breaking/Demos, Proceedings of the 19th International Society for Music Information Retrieval Conference, 2018.
'audio > audio generation' 카테고리의 다른 글
| [논문리뷰] Efficient Neural Audio Synthesis (ICML18) (0) | 2022.07.29 |
|---|---|
| [논문리뷰] SampleRNN: An Unconditional End-to-End Neural Audio Generation Model (ICLR17) (0) | 2022.07.05 |
| [논문리뷰] GANSynth: Adversarial Neural Audio Synthesis (ICLR19) (0) | 2022.06.20 |
| [논문리뷰] Adversarial Audio Synthesis (ICLR19) (0) | 2022.06.20 |
| [논문리뷰] WaveNet: A Generative Model for Raw Audio (arxiv16) (0) | 2022.05.24 |



