논문제목: SampleRNN: An Unconditional End-to-End Neural Audio Generation Model
저자: Soroush Mehri, Kundan Kumar, Ishaan Gulrajani, Rithesh Kumar, Shubham Jain, Jose Sotelo Aaron Courville, Yoshua Bengio
소속: University of Montreal, IIT Kampur, SSNCE
발표: ICLR 2017
논문: https://arxiv.org/abs/1612.07837
코드: https://github.com/soroushmehr/sampleRNN_ICLR2017
오디오 샘플: https://soundcloud.com/samplernn/sets
- SampleRNN
- RNN을 사용하여 오디오를 생성하는 모델
- 오디오의 멀티스케일적인 특성을 모델링하기 위하여 hierarchy RNN을 사용함. 그리고 긴 시퀀스를 짧게 잘라 훈련시키는 truncated BPTT 방법으로 훈련을 시킴.
- 그랬더니 그래도 약간은 들을만한 한 오디오가 생성이 됨. 물론 한번에 한 샘플씩 생성되기 때문에(이름이 힌트) 느린 건 어쩔 수 없음.
Story
타임 시퀀스를 다룰 떄 RNN이 좋은건 모두들 알지만, 오디오 시그널처럼 샘플이 많은 데이터를 다루기엔 쉽지 않았음. 그래서 WaveNet[Oord16]에서는 타임 시퀀스를 다루지만 RNN이 아닌 다른 방법을 썼음. 여기서는 이런저런 테크닉을 적용하여 RNN을 써서도 긴 오디오를 만들수 있다는 것을 보여주겠음.
SampleRNN Model
기본적으로 이전 샘플들을 조건으로 하여 새로운 샘플을 만들어내는 확률을 통해 전체 시퀀스의 확률을 정의함.

그리고 RNN에 대한 수식도 간단하게 살펴보면,

여기서 $\mathcal{H}$는 메모리셀, 즉 GRU나 LSTM등을 의미함. 수식으로는 이렇게만 하면 오디오도 모델링 할 수 있을 것 같지만, 오디오는 태생상 여러 스케일로 되어 있다는 어려움이 있음. 따라서 여기에서는 여러 모듈들의 hierarchy를 만들어 이를 모델링함. 각 모듈들은 다른 temporal resolution을 가짐. 그리고 이들 모든 모듈들은 모두 다 함께 end-to-end 방식으로 훈련됨.
그림으로 한번 보면 다음과 같음.

Frame-Level Modules
프레임-레벨 모듈에서는 단일 샘플을 다루는 대신 (겹쳐지지 않는) 프레임 샘플들을 다루게 됨. 각각은 모두 deep RNN으로 되어 있음. 고로 메모리셀 업데이트는 이전 메모리($h_{t-1}$)과 인풋($inp_t$)을 이용하여 이루어짐.
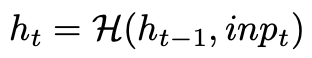
여기서 인풋($inp_t$)은 가장 높은 티어($k=K$)에서는 그냥 인풋 프레임, 중간 티어들($1 < k < K$)에서는 상위 티어로부터 온 벡터와 현재 인풋 프레임을 더해서 사용함.

근데 아래 티어로 데이터를 보내려면 업샘플링을 해야하잖아. 그냥 0을 넣은 뒤 linear convolution함.

Sample-Level Module
마지막 티어 모듈($k=1$)에서는 샘플에 대한 분포를 내보내야 함. 이 때는 이전 샘플들과 함께 위에 모듈에서 온 정보가 함께 사용됨.

여기에서 $e$는 $x$가 임베딩 레이어(다음에 설명)을 거쳐서 나온 값. $FS$는 Frame Size를 의미. 인풋값은 크기가 크지 않기 때문에 그냥 MLP로 모델링해도 차이가 없음(그리고 더 빠름).
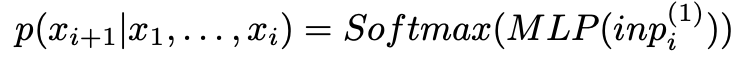
여기에선 Softmax를 사용했는데, 오디오를 가우시안 같은 것으로 표현하는 것보다 discretizing해서 Multinoulli 분포로 표현하는 것이 더 좋은 결과를 보였음. 이제 이 모델을 사용하면 $FS$ 샘플의 윈도우를 처리해서 다음 샘플하나를 만들게 됨. 계속계속 만들면 오디오를 생성할 수 있게 됨.
Output Quantization
샘플은 256개로 quantization됨(즉 8 bit). 16bit을 8bit으로 표현해도 퀄리티 차이가 크게 없었음. 그리고 quantized 된 인풋값을 임베딩($q$ discrete values -> real-valued vector)을 하니 더 좋은 결과를 얻을 수 있었음.
Conditionally Independent Sample Outputs
만일 이전 샘플을 사용하지 않고 단지 위에 모듈에서 온 정보($c$)만 조건으로 하여 샘플을 생성하면 어떨까? 즉 autoregressive 모델이 아니게 됨. 그리고 프레임안에 모든 샘플을 한번에 생성하게 해봄. 결과적으로 이런 'Multi-Softmax' 모델은 제대로된 샘플을 만들어내지 못했음. 즉 샘플들을 함께 joint distribution를 모델링하는 것이 중요했음. 프레임 사이즈도 많이 하는 것보다 1로 하는 것이 가장 좋았음.
Truncated BPTT
RNN은 다 좋은데 긴 시퀀스를 훈련시킬 때 시간이 너무 오래 걸림; 그래서 시퀀스를 짧은 서브시퀀스들로 쪼개고 gradient들을 각 서브시퀀스 시작부분에만 흘러보내는 truncated backpropagation though time 방법으로 효율적으로 훈련시킬 수 있었음. 512 샘플(약 32 ms)길이로 잘랐는데 사실 이는 phoneme의 일부정도 밖에 안되는 작은 시간임. 하지만 프레임-레벨 모듈등의 기법이 함께 사용되어서 제법 그럴듯한 소리가 만들어졌음.
Experiments and Results
다음 3가지 데이터셋을 사용함
Blizzard: 315시간의 여성 스피커의 영어 목소리로 구성된 데이터. 여기서 20.5시간 데이터를 사용.
Onomatopoiea: 3.5시간의 6,738개의 시퀀스. 소리치거나 기침하거나 가뿐 숨을 쉬거나 헐떡이거나 아파서 끙끙대는 등의 사람 목소리로 되어 있음. 51명의 배우의 소리로 상당히 도전적인 데이터셋.
Music: achive.org에서 다운 받은 32개의 베토벤 피아노 소나타(10시간 가량).
이미지로 먼저 보면 아래와 같음.
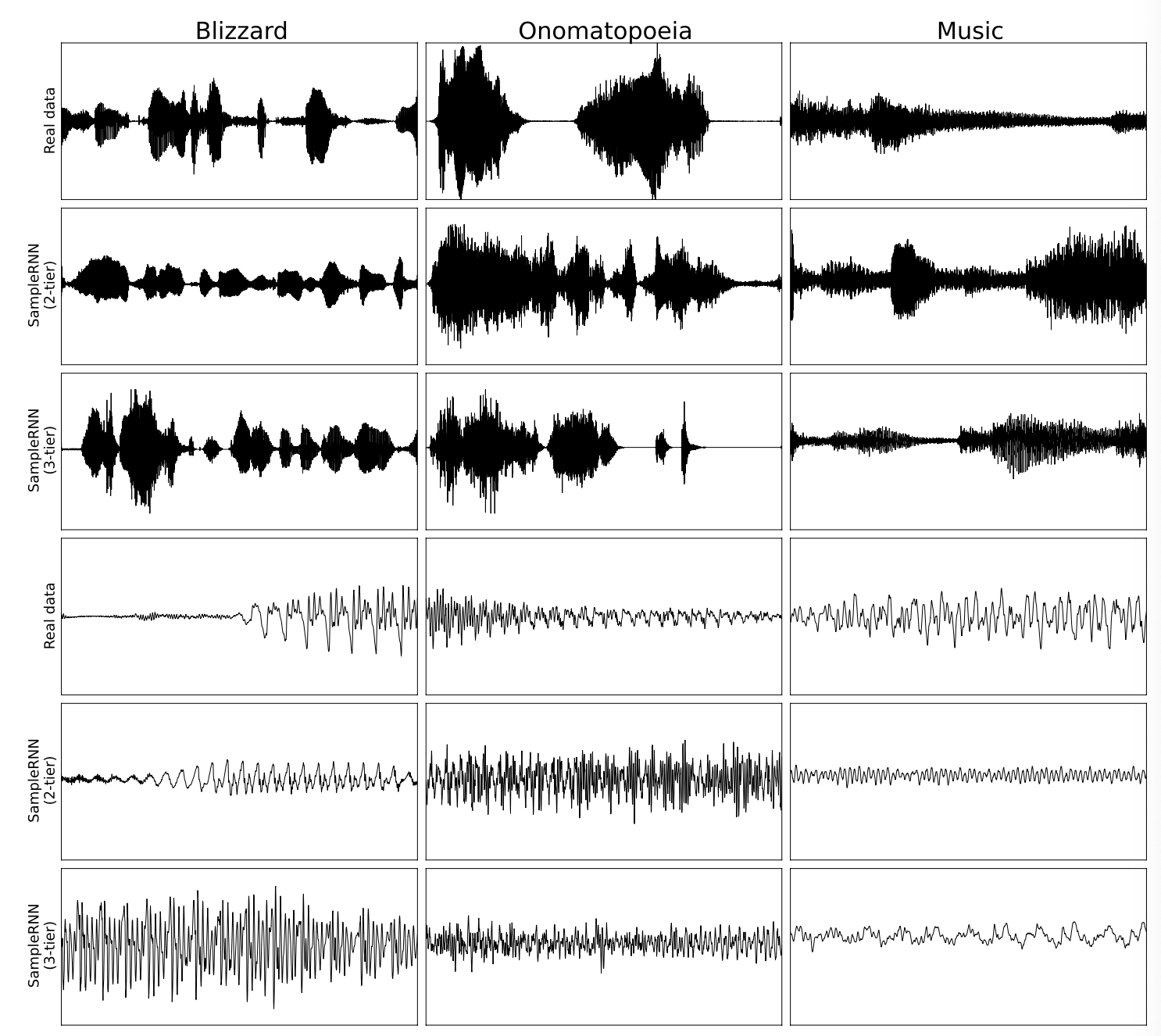
위에 3개는 2초 오디오, 아래 3개는 100 ms의 오디오를 보여줌. 이 모델 자체가 조건을 걸지않은(unconditioned) 모델이므로 real data와 정확히 똑같지는 않음. 하지만 2티어 모델보다는 3티어 모델이 보다 글로벌적인 모습을 잘 잡고 있다는 것을 알 수 있음.
RNN중에서는 GRU와 LSTM 두 모델로 실험함. LSTM의 경우는 forget gate bias를 3으로 설정. 이러면 long-term dependency를 배우는데 좀 더 좋음. real-valued input을 받는 모델로는 RNN-GMM과 SampleRNN-GMM 모델을 만들어서 실험함. 트레이닝 셋으로부터 글로벌 평균과 표준편차를 구해서 사용. 결과적으로 GRU(1024 유닛)가 조금더 나았음.
WaveNet Re-implementation
WaveNet[Oord16]을 자체적으로 다시 구현함. 거의 비슷하게 했지만 몇가지 디테일들과 하이퍼파라미터들은 다르다는 점은 명시(저자들의 컴퓨터의 한계상). 하지만 최선은 다했다고 함. 훈련하는데 GeForce GTX TITAN X로 일주일정도 걸렸음.
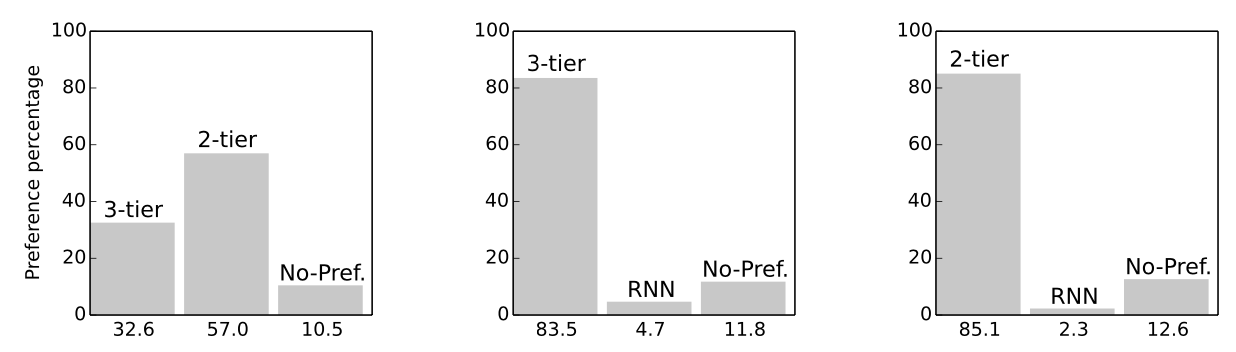
Human Evaluation
Blizzard 데이터셋으로 훈련된 4개의 모델(RNN, SampleRNN(2-tier), SampleRNN(3-tier), WaveNet)에 대해 A/B테스트를 진행. 그 외의 모델들은 결과가 좋지 않아서 탈락. 결과적으로 3티어가 다 이김. 그 다음은 2티어. RNN과 WaveNet 간의 대결은 RNN의 승리.
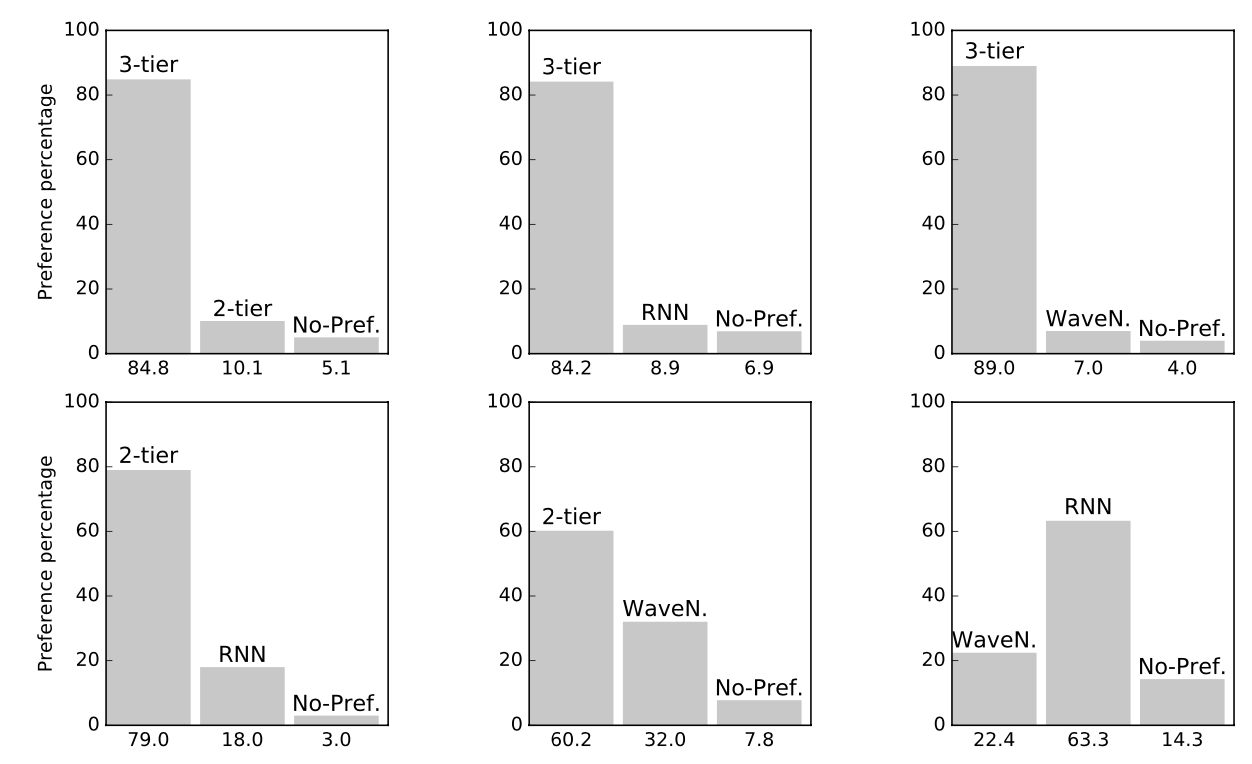
Music 데이터셋을 훈련한 모델도 비교해보았음. 이번에는 모델 3개(RNN, SampleRNN(2-tier), SampleRNN(3-tier)를 A/B 테스트함. 그런데 여기서는 2티어가 3티어를 이김. 아마도 예상치 못한 결과였던 듯. 논문에 별 언급이 없음.
Quantifying Information Retention
제안한 모델이 얼마나 기억력이 좋은지 알아보겠음. 2명의 남/녀 스피커의 오디오 북 데이터로 훈련을 시킴(각각 10시간의 데이터). 그뒤 오디오를 만들어보니, 스피커 ID나 별다른 조건 없이도 같은 스피커의 소리를 만들어낸다는 것을 알 수 있었음.
다른 실험으로 임의로 오디오 중간에 1초간 조용한 부분을 넣고 계속 동일한 스피커 목소리로 이어지는지 알아봄. 남/녀 스피커의 F0으로 classification하는 모델을 만들어 실험을 해보니 83%의 샘플이 같은 스피커의 목소리가 이어진다는 것을 알 수 있었음. 이러한 점은 고정된 윈도우 사이즈를 사용하는 WaveNet같은 모델에서는 나올 수 없는, RNN을 사용하는 모델의 장점이라고 할 수 있음.
RNN을 사용하여 오디오를 생성하는 모델.
그 점 하나만으로도 의미가 있음.
- [Oord16] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016. [논문리뷰]
'audio > audio generation' 카테고리의 다른 글
| [논문리뷰] Efficient Neural Audio Synthesis (ICML18) (0) | 2022.07.29 |
|---|---|
| [논문리뷰] GANSynth: Adversarial Neural Audio Synthesis (ICLR19) (0) | 2022.06.20 |
| [논문리뷰] Adversarial Audio Synthesis (ICLR19) (0) | 2022.06.20 |
| [논문리뷰] Enabling Factorized Piano Music Modeling and Generation with the Maestro Dataset (ICLR19) (0) | 2022.05.26 |
| [논문리뷰] WaveNet: A Generative Model for Raw Audio (arxiv16) (0) | 2022.05.24 |



