제목: Efficient Neural Audio Synthesis
저자: Nal Kalchbrenner, Erich Elsen, Karen Simonyan, Seb Noury, Norman Casagrande, Edward Lockhart, Florian Stimberg, Aaron van den Oord, Sander Dieleman, Koray Kavukcuoglu
소속: DeepMind, Google Brain
발표: ICML 2018
논문: https://arxiv.org/abs/1802.08435
- WaveRNN
- sequential model에서 sampling time을 어떻게 줄일 수 있을지 많은 고민이 담긴 논문
- 1) RNN구조를 이용하고 2) GPU 커널 코딩하고 3) weight prunning으로 weight를 줄이고 4) subscaling으로 병렬 생성을 했더니 많이 빨라짐
- 결과적으로 WaveNet model에 버금하는 퀄리티에 리얼타임보다 4배더 빠른 생성속도 구현
Story
Sequential generative model은 natural language나 natural image/video, 그리고 speech[Oord16][Mehri17]나 music[Simon17][Engel17]등 여러 도메인에서 잘 나가고 있음. 각 샘플마다 conditional probability를 갖고 이들의 합으로 전체 distribution을 표현하는 이 방식은 매우 높은 capacity를 갖는 방식이긴 하지만 그만큼 sampling process가 느리고 스피치나 비디오 같은 고차원 데이터를 생성하기에는 실제로 현실에서 사용하기에 한계가 있음... 이 샘플링과정이 효율적이면 참 좋겠는데.. 어떻게 하면 효율적으로 만들 수 있을까. 열심히 머리를 굴려보니?!?
Introduction
뉴럴네트워크를 사용한 모델에서 전체 샘플링 시간 $T(u)$는 수학적으로 어떻게 표현할 수 있을까? 먼저 샘플의 개수($u$)에다가 하나의 샘플을 생성하는데 걸리는 시간과 곱하면 될듯. 샘플을 생성하는데 걸리는 시간은 $N$개의 레이어에서 computation time $c(op_i)$와 overhead $d(op_i)$의 합으로 표현할 수 있을 듯. 정리하면 아래와 같음.
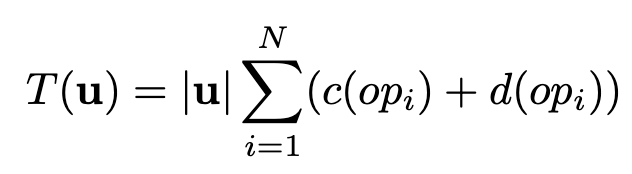
이 식을 보면 샘플개수($u$)가 늘어나면 당연히 시간이 늘어날거임. 만일 WaveNet처럼 깊은 구조를 사용하면 $N$이 늘어나서 또 시간이 늘어날거임. 또한 layer가 넓거나 혹은 파라미터의 수가 많다면 $c(op_i)$가 늘어나서 시간이 늘어날 거임. 그리고 각 operation을 launch하는데 걸리는 시간이 늘어난다면 $d(op_i)$가 늘어나서 또 시간이 늘어날거임. 이 논문에서는 생성 오디오의 퀄리티의 차이가 거의 없게 하면서도 이 4가지 요소를 어떻게 줄여서 전체 시간을 줄일 것인지에 대해서 고민해봄.
1) 먼저 적은 수의 $N$을 갖는 sequence model을 제안하는 것부터 시작함. 제안하는 모델 WaveRNN은 single-layer RNN인데, 여기에 효율적으로 16비트 오디오 샘플을 만들기 위해 디자인된 두개의 softmax 레이어를 사용함. 실험결과 896개의 유닛을 사용하면 가장 큰 WaveNet모델과 비슷한 성능을 갖는 결과를 생성할 수 있었는데, 여기에서는 하나의 샘플을 만들때 단지 $N$=5개의 행렬-벡터곱만이 필요했음. 반면에 동일한 수준의 WaveNet에서는 두개의 레이어로 되어 있는 residual block 30개가 필요했는데 이러면 $N$=60개의 행렬-벡터 곱이 필요하게 됨.
2) 다음으로 overhead $d(op_i)$를 줄이기 위하여 custome GPU operation을 구현하였음. 결과 리얼타임의 4x 수준으로 24kHz의 16비트 오디오를 생성할 수 있었음. WaveNet 모델에서 최선을 다해서 GPU kernel을 구현을 해봤는데 리얼타임의 0.3x 정도밖에 빠르게 만들지 못했음.
3) 네트워크의 파라미터 숫자를 줄여 $c(op_i)$ 계산 시간을 빠르게 하기 위해서 weight prunning방식을 적용했음. 실험결과 large sparse WaveRNN이 small dense WaveRNN 보다 더 좋은 결과를 보였음.
4) 마지막으로 subscaling 방법으로 $u$ 숫자를 줄여보겠음. 하나의 tensor $A$(scale=$L$)는 여러개의 sub-tensor $B$(scale=$L/B$)로 나뉠 수 있음. sub-tensor $B$들은 순서대로 생성되고 각각 이전 sub-tensor들을 조건으로 사용함. 이러한 subscaling 방식은 여러 샘플들을 한번에 생성할 수 있게 함. 현실적으로 어느정도의 subscale을 사용할 수 있을지 실험한 결과 $B$=16정도여도 오디오의 퀄리티에 큰 차이가 없는 정도 수준으로 생성되는 것을 알 수 있었음.
Wave Recurrent Neural Networks
기존 방법들과 다르게 적은 operation을 사용하면서도 충분한 표현력을 갖는 모델을 찾다가 RNN을 사용할 수 있겠다라는 생각이 들었음. 제안하는 WaveRNN의 구조를 계산식으로 나타내면 아래와 같음.
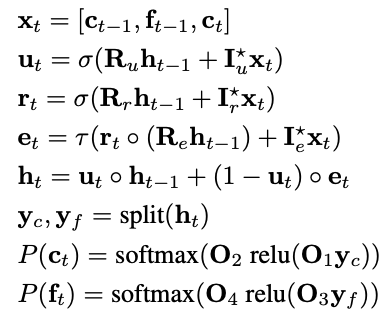
각각 3개의 게이트 $u_t$, $r_t$, $e_t$를 만드는 역할을 하는 $R_u$, $R_r$, $R_e$는 $R$로 합쳐져서 하나의 행렬-벡터 곱으로 계산됨.
16비트 오디오의 경우 이를 softmax로 하나씩 생성한다면 모두 $2^16$개의 아웃풋이 있는 softmax를 이용해야 함. 이 크기를 줄이기 위하여 16비트 오디오를 반으로 쪼개서 coarse한 부분($c$), fine한 부분($f$)으로 나눠서 처리함. 먼저 $c$ 부분을 소프트맥스로 구하고 그다음 $f$ 부분을 소프트맥스로 구함. 이러면 $2^8$개의 아웃풋이 있는 softmax를 이용할 수 있음. 이를 dual softmax layer라고 부르고 그림으로 나타내면 아래와 같음.
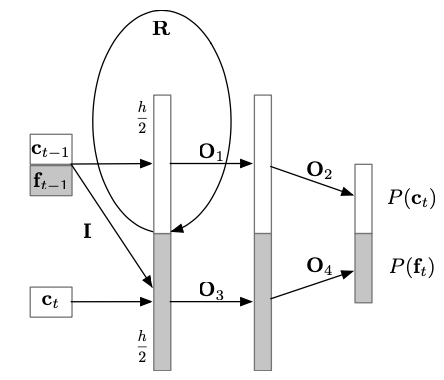
WaveRNN Sampling on GPU
네트워크 구조의 변경으로 $N$=60이 필요했던 WaveNet을 $N$=5인 WaveRNN으로 줄였음. 하지만 실제 구현에서 해결해야 하는 문제가 발생하는데, 먼저 1) GPU메모리 크기가 엄청 필요하고 2) operation에 대한 오버해드 시간도 많이 걸림.
일단 896개의 unit을 갖는 WaveRNN은 3M개의 파라미터를 갖는데, 24000 샘플에 대해서 이 모델을 각각 실행한다고 가정하고 계산해보니 288GB의 메모리가 필요하게 됨. 또한 GPU에서 하나의 operation을 launch할 때 5ms정도의 오버해드가 있는데, WaveRNN은 샘플당 $N$=5이므로 1초에 최대 40,000 샘플밖에 만들지 못함. 하지만 이건 이론이고 현실은 다름. 실제 구현해서 돌려보니 1초에 1600샘플을 만드는 것이 최고였음.
그래서 sampling procedure를 따로 하나의 persistent GPU operation로 구현함. 이를 샘플링을 시작할 때 GPU안에다가 넣는데, P100 GPU의 경우 3.67M의 full-precision register가 들어있어서 충분히 안에 들어갈 수 있음. 이 operation은 샘플링 끝날 때까지 계속 안에 남아있음. 그리고 하나의 operation이기 때문에 launch overhead도 문제가 되지 않음.
state사이즈를 896으로 정한 것도 이유가 있음. P100 GPU는 56개의 multi-processor로 되어 있는데, 여기에 GPU의 full register file에 접근할 수 있게 하는 최소 warp의 개수가 8임. 따라서 state사이즈는 56*8=448의 배수여야지 효율적이고, 그 중에서 가능한 register space에 딱 맞는 것이 896였음. 이렇게 GPU kernel을 구현하니 수백배 빨라졌음. 1초당 96,000개의 샘플을 만들 수 있었음. 심지어 WaveNet도 1초에 8,000샘플을 만들 수 있게 만들었음.
Sparse WaveRNN
이제 다음으로 각 operation마다 computation $c(op_i)$양을 줄이는 방법을 소개하겠음. 물론 히든 유닛을 줄이면 됨. 하지만 퀄리티가 많이 떨어지게 됨. 대신에 네트워크에서 0이 아닌 weight의 개수를 줄이는 방법을 이용하면 됨.
Weight Sparsification Method
처음에는 weight matrix들은 dense함. 500스텝마다 weight들을 정렬하여 가장 작은 $k$개의 weight를 0으로 만들어버림. 실제로는 $k$를 쓰지는 않고 전체 weight 개수의 fraction $z$ 를 사용하는데, 이 개수는 $0$에서부터 점차 커져서 target sparsity $Z$까지 증가함.
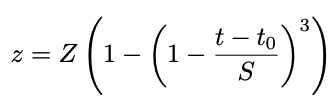
$t_0$은 weight prunning이 시작한 스텝, $S$는 pruning step의 총 개수. $t_0$=1000, $S$=200k를 사용했고, 훈련은 모두 500k 스텝 진행하였음. 간단하지만 실제적으로 적용하기 쉬운 형태임. 이 방법으로 3개의 gate matrice $R$의 weight를 줄였음.
Structured Sparsity
sparsity mask를 어떻게 인코딩해야지 효율적일까? memory overhead를 줄이기 위하여 structured sparsity를 이용해보았음. 무슨 말이냐면 weight를 각각 보는 것이 아니라 block으로 함께 보고 죽든지 살든지 함께 가도록 하는 것임. 계산할 때는 block 안의 weight 평균을 이용함. 실험을 해보니 $m$=16 개의 weight가 함께 처리되도 성능에 큰 영향이 없었음. 하지만 메모리는 $1/m$만큼 줄거임. 4x4와 16x1 block 모양을 실험해보았는데 둘다 잘되긴 했는데 16x1이 조금 더 나았음.
Subscale WaveRNN
이제 마지막으로 $|u|$값을 줄여보도록 함. 단순하게 $u$값을 줄이는건 별 말이 안되고, 여기에서는 각 스텝마다 샘플을 하나씩 생성하는 것이 아니라 $B$ 샘플씩, 즉 batch형태로 생성하는 방식을 제안함. 그러면 시간은 이렇게 될거임.
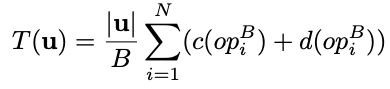
batch로 생성을 하면 여러 프로세서들을 통해서 생성할 수도 있고 계산시에 weights가 재사용되기도 해서 확실히 속도적인 측면에서 이득이 있음. 그런데 이렇게 sequence model에서 batch형태로 생성을 하려면 어느정도 local dependency를 희생해야만 함. 여기에서는 distant(멀리 떨어져 있는) past dependency와 future dependency를 어느정도 희생하면서 $B$개의 샘플을 동시에 생성할 수 있는 방법을 제안함.
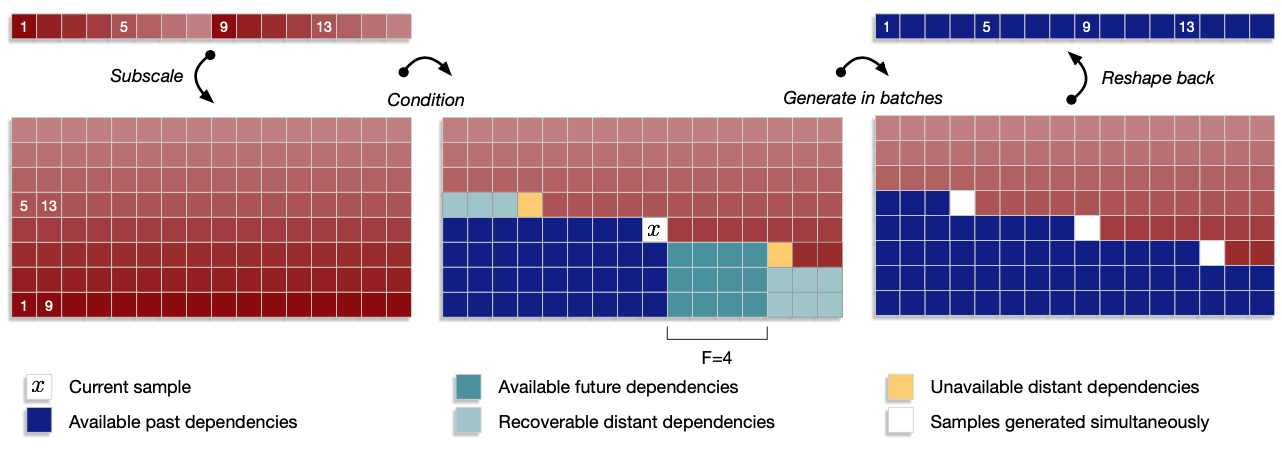
Subscale Dependency Scheme
먼저 tensor $u$로부터 $B$개의 sub-tensor의 셋을 만듬. 즉 $u$를 subscale slice해서 만든다는 의미(위의 이미지 왼쪽 참고). 이제 $u$안의 각 값들은 아래와 같은 dependency를 갖게 됨.
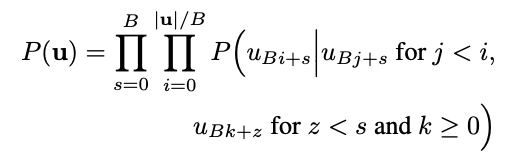
즉 위의 그림 중간을 보면 현재 샘플이 $x$일때 그 왼쪽과 아래 파란색은 모두 past dependency라는 의미. 그리고 이전까지의 sub-tensor들의 future context도 고려하게 함. 이를 위해서 masked dilated CNN을 사용하여 이를 모델링하게 함(여기서 mask는 과거에 대한 mask를 의미함. 5단계의 dilation을 갖고 총 10개의 레이어로 구성되었음. 이 별도의 모델은 병렬처리가 가능하므로 전체 모델 속도에는 별로 영향을 미치지 않음)
Batched Sampling
어떤 상수값 future horizon $F$에 대하여 $k > i + F$ 인 값에 대해서는 dependency가 매우 약하게 됨(그림 중간 노란 네모들). 그래서 이 만큼 멀리 떨어진 부분(distant)은 동시에 샘플링을 하게 됨. 그런데 이렇게 떨어진 샘플들을 생성하기 때문에 어느정도 lag(=$B \times F$)이 발생할 수 밖에 없음. 하지만 전체 오디오의 샘플길이에 비해서 이정도 lag은 무시할 수 있을만한 수준. 이렇게 동시에 batch형태로 샘플을 생성하면 기본적인 텐서플로우 구현만으로도 리얼타임 수준의 속도를 낼 수 있었음.
Fused Subscale WaveRNN
WaveRNN에서 한번에 16비트 이상, 예를 들어 32비트를 한 스텝에 생성하는 모델도 생각해볼 수 있음. 즉 Subscale WaveRNN 2x ($B$=2라는 의미)를 만들고 WaveRNN의 히든 스테이트를 반으로 더 나눔. 그리고 4비트값을 생성하는 8개의 소프트맥스를 이용하여 32비트 값을 생성함. $F$=2로 단순하게 두고 별도의 네트워크는 이용하지 않음. 이렇게 만들어도 퀄리티가 별로 떨어지지 않았고, 속도는 리얼타임의 10배 수준까지 만들어낼 수 있었음.
Experiments
데이터는 내부 데이터를 사용함(44시간 북미 영어 스피커).
WaveRNN Quality Evaluation & Speed
먼저 WaveNet과 다양한 사이즈의 WaveRNN의 MOS점수를 비교해보면 유닛의 개수가 늘어날 수록 품질은 더 좋아지는 것을 알 수 있음. 2048모델은 거의 60레이어 WaveNet과 동등한 수준을 만든다는 것을 알 수 있음(Table 3).

이를 A/B 테스트를 해봐도 WaveNet과 WaveRNN-896의 차이는 별로 거의 없다는 것을 알 수 있음(Table 1)

Sparse WaveRNN Quality Evaluation
아래 그래프는 sparsity를 증가시켰을 때 NLL(Negative Log-Likelihood)값이 어떻게 변하는지를 보여줌. 먼저 파라미터가 많으면(384 vs 224) 더 작은 NNL를 갖음. sparsity를 높일 수록 NNL이 떨어지는데 이는 뉴런들을 sparse하게 연결하면 더 좋다는 것을 보여줌. 98%까지는 이러한 경향이 나타났음.
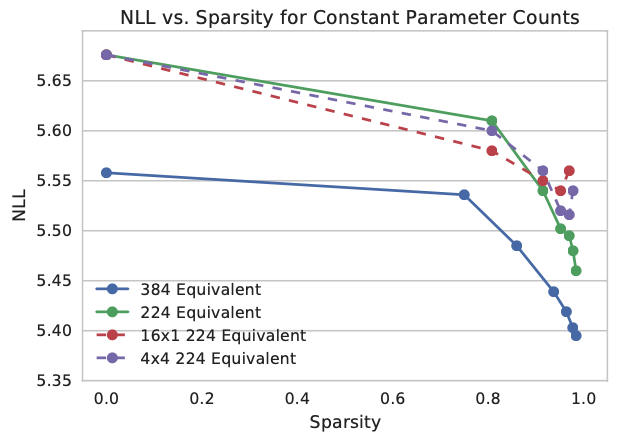
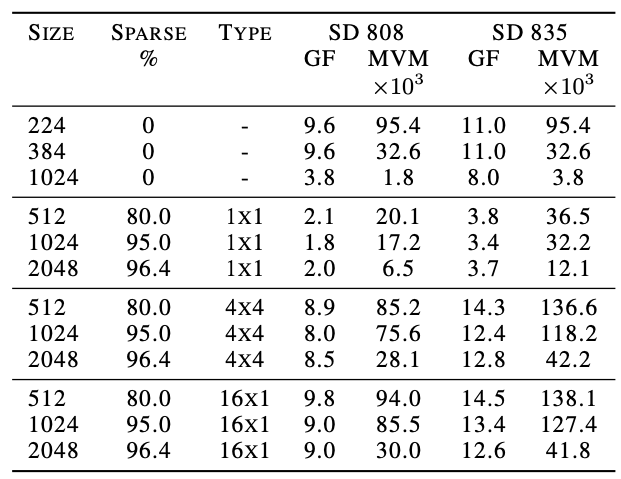
블럭의 모양도 살펴보면, 4x4가 좀 더 낮은 NLL을 기록했는데 속도면에서는 16x1 블락이 더 나았음. 신기하게도 이렇게 블럭을 사용하는 것이 그냥 unstructured sparsity를 사용하는 것보다 (low sparsity level에서는) 더 좋은 결과를 보여주었음. 블럭을 사용하지 않으면 인퍼런스 속도가 상당히 느렸음. 아래에서는 여러 모델과 블럭에 따른 연산속도를 보여줌(이때 당시 모바일폰에서 널리 사용되었던 mobile CPU로 측정).
Subscale WaveRNN Quality Evaluation
B=8과 16에 대해서 실험을 했는데 WaveRNN 8x 버전이 WaveRNN-896과 동등한 수준의 결과는 보였음(위 Table 3참고). 16x버전과 일반 버전과 A/B 버전을 테스트한 결과도 별 차이가 없었음(위 Table 1 참고). 이는 subscale dependency가 잘 작동한다는 것을 의미함. sequential model 자체가 dependency가 엄청 중요한 모델인데, 실제로 해보면 어느정도의 dependency를 잃어도 괜찮다는 의미로 해석할 수 있음.
' efficient' 를 위하여 참 많은 일을 한 노력의 결실 논문ㅠㅜ
- [Oord16] A.van den Oord, S.Dieleman, H.Zen, K.Simonyan, O.Vinyals, A.Graves, N.Kalchbrenner, A.Senior, K.Kavukcuoglu. WaveNet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016. [논문리뷰]
- [Engel17] Engel, J., Resnick, C., Roberts, A., Dieleman, S., Eck, D., Simonyan, K., and Norouzi, M. Neural audio synthesis of musical notes with wavenet autoencoders. CoRR, abs/1704.01279, 2017.
- [Mehri17] S.Mehri, K.Kumar, I.Gulrajani, R.Kumar, S.Jain, J.Sotelo, A.Courville, Y.Bengio. SampleRNN: An unconditional end-to-end neural audio generation model. ICLR 2017. [논문리뷰]
- [Simon17] Simon, I. and Oore, S. Performance RNN: Generating music with expressive timing and dynamics. https://magenta.tensorflow.org/ performance-rnn, 2017.



