 [논문리뷰] FastSpeech: Fast, Robust and Controllable Text to Speech (NeurIPS19)
제목: FastSpeech: Fast, Robust and Controllable Text to Speech 저자: Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu 소속: Zhejiang University, Microsoft Research, Microsoft STC Asia 발표: NeurIPS 2019 논문: https://arxiv.org/abs/1905.09263 오디오샘플: https://speechresearch.github.io/fastspeech/ - FastSpeech - 일단 기본적인 Transformer [Li19] 모델을 훈련시켜 teacher 모델을 만듬. 이 모델을 이용하여 attention a..
[논문리뷰] FastSpeech: Fast, Robust and Controllable Text to Speech (NeurIPS19)
제목: FastSpeech: Fast, Robust and Controllable Text to Speech 저자: Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu 소속: Zhejiang University, Microsoft Research, Microsoft STC Asia 발표: NeurIPS 2019 논문: https://arxiv.org/abs/1905.09263 오디오샘플: https://speechresearch.github.io/fastspeech/ - FastSpeech - 일단 기본적인 Transformer [Li19] 모델을 훈련시켜 teacher 모델을 만듬. 이 모델을 이용하여 attention a..
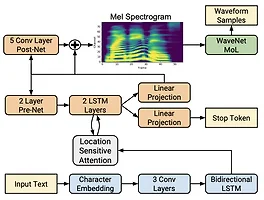 [논문리뷰] Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions (ICASSP18)
논문: Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions 저자: Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu 소속: Google, University of California, Berkeley 발표: ICASSP 2018 논문: https://arxiv.org/abs/1712.05884 오디오샘플: https://goog..
[논문리뷰] Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions (ICASSP18)
논문: Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions 저자: Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu 소속: Google, University of California, Berkeley 발표: ICASSP 2018 논문: https://arxiv.org/abs/1712.05884 오디오샘플: https://goog..
 [논문리뷰] Tacotron: Towards End-to-End Speech Synthesis (INTERSPEECH17)
제목: TACOTRON: Towards End-to-End Speech Synthesis 저자: Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous 소속: Google 발표: INTERSPEECH 2017 논문: https://arxiv.org/abs/1703.10135 오디오샘플: https://google.github.io/tacotron/ - Tacotron - 정말로 처음부터 끝까지 한 번에 다하고..
[논문리뷰] Tacotron: Towards End-to-End Speech Synthesis (INTERSPEECH17)
제목: TACOTRON: Towards End-to-End Speech Synthesis 저자: Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous 소속: Google 발표: INTERSPEECH 2017 논문: https://arxiv.org/abs/1703.10135 오디오샘플: https://google.github.io/tacotron/ - Tacotron - 정말로 처음부터 끝까지 한 번에 다하고..







